[CS229] [9] Lecture 9 - Approx/Estimation Error & ERM
1. Assumptions
- 이번 Lecture에선 미리 두가지 가정을 하고 간다.
- 첫 번째: (x,y) ~ D를 만족하는 data distribution D가 존재한다.
- 두 번째: 모든 Samples들은 Independent하다.
2. Bias & Variance
우리는 Lecture 8에서 다음과 같이 Underfitting과 Overfitting에 대해서 알아보았다.

- 이걸 bias와 Variance입장에서 한번 봐보자. (다음 4개의 plot을 보면 쉽게 이해 가능하다.)
- bias가 커질수록 Under-fitting되고, Variance가 커질수록 Over-fitting된다.
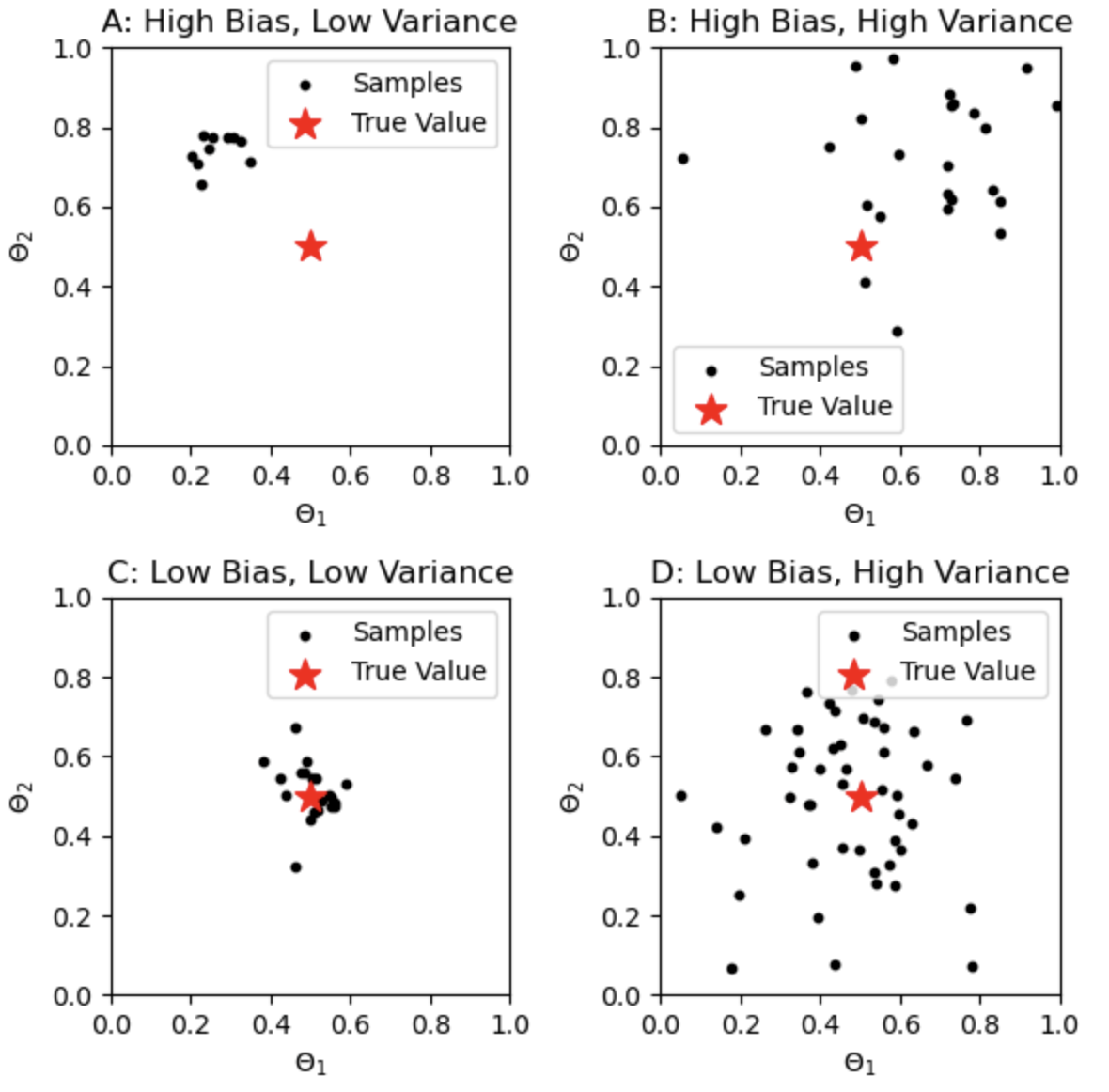
- 여기서 기존의 데이터셋의 크기가 커지면 커질수록 Variance는 작아진다고 한다.
- 그래서 모델을 학습할 때 데이터를 늘리면 좋은 이유가 여기서 나오게 된다.
- 그러면 우리는 결과적으로 Variance를 작게 가져가는 방법에 대해서 궁금하게 될 것이다.
3. fighting variance
- Variance를 줄이는 방법은 다음과 같다.(bias를 줄이는 방법은 Variance를 높이면 된다고 한다...모델의 크기를 늘리거나..)
"""
i) Data의 수를 늘린다.
- 기존의 데이터셋의 크기가 커지면 커질수록 Variance는 작아진다
ii) Regularization
- Regularization은 기존의 높은 분산의 일부분을 편향으로 바꾸고 분산을 낮춘다고 한다.
"""
4. ERM(Empirical risk minimization)
- ERM은 머신러닝에서 모델을 훈련하는 기본적인 원리 중 하나로,
- 주어진 데이터 샘플에서의 평균적인 risk를 minimization하는 기법이다.
- ERM의 기본 아이디어는 다음과 같다.
- 어떤 모델 f가 주어진 입력 x에 대해 예측값 f(x)을 출력한다고 가정해보자.
- 우리가 원하는 것은 이 모델이 실제 데이터 분포 P(x,y)에 대해 loss를 최소화하는 것일것이다.
- 하지만 실제 데이터의 분포를 모르기 때문에, 우리가 가진 유한한 샘플 데이터를 사용하여 손실을 최소화하는 방법을 찾는다.
- ERM에서는 데이터 샘플을 이용하여 Empirical Risk을 계산하고, 이를 minimization하는 방향으로 모델을 학습시킨다.
- Empirical Risk는 주어진 훈련 데이터 {x,y}에 대해 손실함수 L(y,f(x))의 평균값을 계산하는 방시으로 정의된다.
- 즉, Empirical Risk는 훈련 데이터에서의 평균 손실을 의미한다.
- ERM은 이 Empirical Risk을 minimization하는 것이라고 보면 된다.
- 여기서, Train loss만 감소시키게 되면 Overfitting이 된다.
- 그래서, Regularization을 적용시켜 Overfitting을 방지한다.