
0. Reference
https://arxiv.org/abs/1803.08494
Group Normalization
Batch Normalization (BN) is a milestone technique in the development of deep learning, enabling various networks to train. However, normalizing along the batch dimension introduces problems --- BN's error increases rapidly when the batch size becomes small
arxiv.org
1. Introduction
- Batch Normalization은 딥러닝에서 흔히 쓰이는 기법중 하나이다.
- 하지만 이러한 Batch Normalization은 batch size에따라 성능이 좌우되게 된다.
- 다음 그래프는 Batch size가 줄어들면서 성능이 점점 악화되는 모습을 보인다.

- 해당 논문에선 이러한 Batch Normalization의 대안으로 Group Normalization을 제안한다.
- 간단히 다음과 같이 Normalization한다고 생각하면 된다.
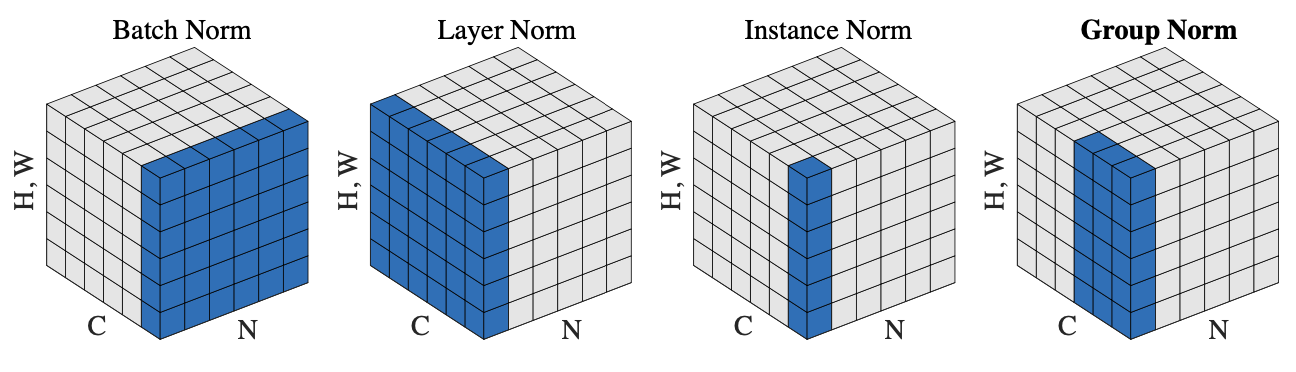
- 본 논문에서 Layer Normalinzation이 한계가 존재하고 Group Normalization이 보다 성능이 좋다고 한다.
- Group Normalization에 대해 자세히 알아가보자.
2. Group Normalization
- Group Normalization의 Motivation은 다음과 같다.
- 주방에서 다양한 재료(채소, 고기, 양념 등)를 그룹별로 분류한 뒤 각각의 그룹을 따로 준비하는 과정으로 생각해 보자.
- 모든 재료를 한꺼번에 처리하면 효율이 떨어질 수 있지만,
- 비슷한 특성을 가진 재료를 함께 다루면 더 효율적으로 요리를 준비할 수 있는 것처럼,
- 비슷한 성질의 특징들을 그룹으로 묶어 정규화하면 모델이 더 나은 학습을 할 수 있게 된다.
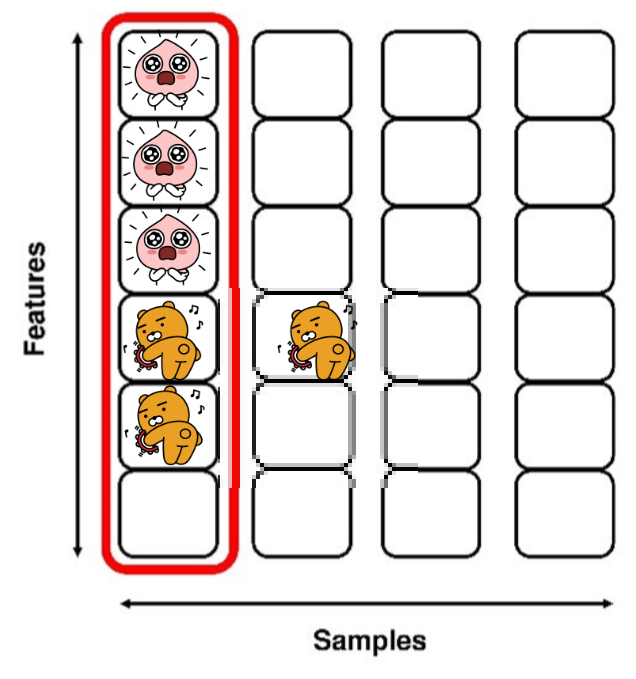
- 수식은 크게 중요하진 않을거 같아서 작성하지 않았지만,
- 간단하게 한 Samples에 대해서 각각 같은 이모티콘에 해당하는 부분을 Normalization한다고 생각하면 된다.
3. Pytorch 구현
import torch
import torch.nn as nn
class GroupNorm(nn.Module):
def __init__(self, num_channels, num_groups, eps=1e-5, affine=True):
super(GroupNorm, self).__init__()
self.num_groups = num_groups
self.eps = eps
self.affine = affine
# Scale and shift parameters (gamma and beta) if affine=True
if self.affine:
self.gamma = nn.Parameter(torch.ones(num_channels))
self.beta = nn.Parameter(torch.zeros(num_channels))
else:
self.gamma = None
self.beta = None
def forward(self, x):
N, C, H, W = x.shape
# Reshape the input to (N, num_groups, C // num_groups, H, W)
x = x.view(N, self.num_groups, C // self.num_groups, H, W)
# Compute mean and variance for each group
mean = x.mean(dim=(2, 3, 4), keepdim=True)
var = x.var(dim=(2, 3, 4), keepdim=True, unbiased=False)
# Normalize the input
x_normalized = (x - mean) / torch.sqrt(var + self.eps)
# Reshape the normalized tensor back to the original shape
x_normalized = x_normalized.view(N, C, H, W)
# Apply scale (gamma) and shift (beta)
if self.affine:
x_normalized = self.gamma.view(1, C, 1, 1) * x_normalized + self.beta.view(1, C, 1, 1)
return x_normalized
4. Experiment

- 해당 그래프는 GN이 BN과 거의 유사한 성능을 보이는 것을 알 수 있다.
- 추가적으로 IN과 LN에 비해 더 성능이 우수하다는 것을 보인다.
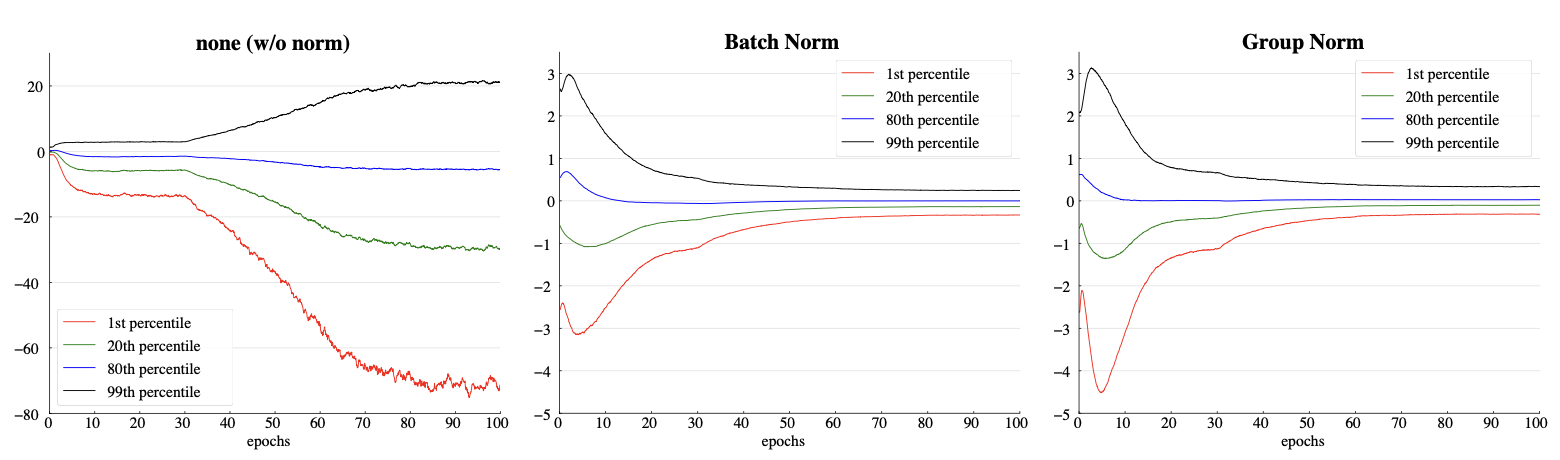
- 해당 그래프는 에폭당 Hidden layer의 feature distribution을 나타낸 것이다.
- BN과 유사하게 Normalization된 모습을 볼 수 있다.
'Paper Review(논문 리뷰) > Deep Learning' 카테고리의 다른 글
| [논문 리뷰] [Deep Learning] Long Short-Term Memory (1) | 2025.02.04 |
|---|---|
| [논문 리뷰] [Deep Learning] Machine Learning Students Overfit to Overfitting (1) | 2025.02.01 |
| [논문 리뷰] [Deep Learning] Layer Normalization (0) | 2025.01.21 |
| [논문 리뷰] [Deep Learning] An introduction to ROC analysis (0) | 2025.01.19 |
| [논문 리뷰] [Deep Learning] Adam : A method for stochastic optimization (0) | 2025.01.10 |
0. Reference
https://arxiv.org/abs/1803.08494
Group Normalization
Batch Normalization (BN) is a milestone technique in the development of deep learning, enabling various networks to train. However, normalizing along the batch dimension introduces problems --- BN's error increases rapidly when the batch size becomes small
arxiv.org
1. Introduction
- Batch Normalization은 딥러닝에서 흔히 쓰이는 기법중 하나이다.
- 하지만 이러한 Batch Normalization은 batch size에따라 성능이 좌우되게 된다.
- 다음 그래프는 Batch size가 줄어들면서 성능이 점점 악화되는 모습을 보인다.
- 해당 논문에선 이러한 Batch Normalization의 대안으로 Group Normalization을 제안한다.
- 간단히 다음과 같이 Normalization한다고 생각하면 된다.
- 본 논문에서 Layer Normalinzation이 한계가 존재하고 Group Normalization이 보다 성능이 좋다고 한다.
- Group Normalization에 대해 자세히 알아가보자.
2. Group Normalization
- Group Normalization의 Motivation은 다음과 같다.
- 주방에서 다양한 재료(채소, 고기, 양념 등)를 그룹별로 분류한 뒤 각각의 그룹을 따로 준비하는 과정으로 생각해 보자.
- 모든 재료를 한꺼번에 처리하면 효율이 떨어질 수 있지만,
- 비슷한 특성을 가진 재료를 함께 다루면 더 효율적으로 요리를 준비할 수 있는 것처럼,
- 비슷한 성질의 특징들을 그룹으로 묶어 정규화하면 모델이 더 나은 학습을 할 수 있게 된다.
- 수식은 크게 중요하진 않을거 같아서 작성하지 않았지만,
- 간단하게 한 Samples에 대해서 각각 같은 이모티콘에 해당하는 부분을 Normalization한다고 생각하면 된다.
3. Pytorch 구현
import torch
import torch.nn as nn
class GroupNorm(nn.Module):
def __init__(self, num_channels, num_groups, eps=1e-5, affine=True):
super(GroupNorm, self).__init__()
self.num_groups = num_groups
self.eps = eps
self.affine = affine
# Scale and shift parameters (gamma and beta) if affine=True
if self.affine:
self.gamma = nn.Parameter(torch.ones(num_channels))
self.beta = nn.Parameter(torch.zeros(num_channels))
else:
self.gamma = None
self.beta = None
def forward(self, x):
N, C, H, W = x.shape
# Reshape the input to (N, num_groups, C // num_groups, H, W)
x = x.view(N, self.num_groups, C // self.num_groups, H, W)
# Compute mean and variance for each group
mean = x.mean(dim=(2, 3, 4), keepdim=True)
var = x.var(dim=(2, 3, 4), keepdim=True, unbiased=False)
# Normalize the input
x_normalized = (x - mean) / torch.sqrt(var + self.eps)
# Reshape the normalized tensor back to the original shape
x_normalized = x_normalized.view(N, C, H, W)
# Apply scale (gamma) and shift (beta)
if self.affine:
x_normalized = self.gamma.view(1, C, 1, 1) * x_normalized + self.beta.view(1, C, 1, 1)
return x_normalized
4. Experiment
- 해당 그래프는 GN이 BN과 거의 유사한 성능을 보이는 것을 알 수 있다.
- 추가적으로 IN과 LN에 비해 더 성능이 우수하다는 것을 보인다.
- 해당 그래프는 에폭당 Hidden layer의 feature distribution을 나타낸 것이다.
- BN과 유사하게 Normalization된 모습을 볼 수 있다.
'Paper Review(논문 리뷰) > Deep Learning' 카테고리의 다른 글
| [논문 리뷰] [Deep Learning] Long Short-Term Memory (1) | 2025.02.04 |
|---|---|
| [논문 리뷰] [Deep Learning] Machine Learning Students Overfit to Overfitting (1) | 2025.02.01 |
| [논문 리뷰] [Deep Learning] Layer Normalization (0) | 2025.01.21 |
| [논문 리뷰] [Deep Learning] An introduction to ROC analysis (0) | 2025.01.19 |
| [논문 리뷰] [Deep Learning] Adam : A method for stochastic optimization (0) | 2025.01.10 |