
0. Reference
https://arxiv.org/abs/2212.06515
AdvMIL: Adversarial Multiple Instance Learning for the Survival Analysis on Whole-Slide Images
The survival analysis on histological whole-slide images (WSIs) is one of the most important means to estimate patient prognosis. Although many weakly-supervised deep learning models have been developed for gigapixel WSIs, their potential is generally rest
arxiv.org
0.1. Dataset and Source code
https://github.com/liupei101/AdvMIL
GitHub - liupei101/AdvMIL: [MedIA 2024] The implementation of AdvMIL: Adversarial Multiple Instance Learning for the Survival An
[MedIA 2024] The implementation of AdvMIL: Adversarial Multiple Instance Learning for the Survival Analysis on Whole-Slide Images - liupei101/AdvMIL
github.com
1. Introduction
- 생존 분석(Survival Analysis)는 시간에 따른 사건 발생 데이터를 분석하는 통계적 접근법이다.
- 본 논문에선 WSI(Whole-Slide Images)를 통해 Survival Analysis를 예측하는 모델에 대해 설명하고 있다.
- 일반적인 자연 이미지와는 달리 WSI는 초고해상도(40,000 x 40,000 pixel)로 이루어져 있다.
- 이러한 높은 해상도는 WSI의 Global representation learning에 큰 어려움을 가져오게 된다.
- 이러한 어려움을 해결하기위해 세 단계로 이루어진 WSL(Weakly Supervised Learning)을 따른다.
i) WSI patching
--> 초고해상도 WSI를 작은 patch 단위로 분할
ii) patch-level feature extracting
--> 각 패치의 특징을 추출
iii) slide-level representation learning
--> 각 패치의 특징을 가지고 패치간의 관계를 학습하여 WSI의 global representation을 생성

- 이 과정을 embedding-level Multiple Instance Learning(MIL)이라고 한다.
- 패치 간의 상관관계에 따라 MIL은 세 가지 범주로 나뉜다.
1. Cluster-based
2. Graph-based
3. Sequence-based
1.1. WSI data 부족
- 기존의 모델들은 slide-level labels을 활용하여 fully-supervised learning방식으로 학습한다.
- 따라서, 충분한 labeled data가 확보되지 않으면 모델의 generalization이 저하된다.
- 현재 WSI 데이터셋의 환자 수는 약 500명으로 제한되어있다.

- ImageNet(10000개 이상의 sample)에 비하면 소규모 데이터 환경에 머물러 있음을 보여준다.
- 이는 모델의 generalization에 부정적인 영향을 미치게 된다.
- 해당 문제를 완화하고자 Generative Adversarial Network(GAN)이라는 생성모델로 해결한다.
- GAN은 복잡한 데이터 분포를 implicitly sampling하여 추정한다.
- point estimation이 아닌, distribution estimation에 가까워진다.
- GAN의 generator-discriminator 구조는 fake 또는 unlabeled data를 입력으로 사용 가능하다.
- 그래서 semi-supervised learning을 가능하게 해준다.
- 이러한 특성 때문에 소규모 데이터 환경에 대해서 모델의 generalization을 높일 수 있다.
- 그렇기에, GAN은 survival analysis뿐만 아니라, 다양한 의료 영상 분석 분야 등등에 활용된다.
1.2. Adv-MIL?
- Adv-MIL == GAN + MIL
2. Related Work
2.1. Survival analysis of WSI
(1) MIL(Multiple-Instance Learning) Network
- WSI에서 global representation learning을 위해 MIL이 많이 사용되었다고 한다.
- 이는, ent-to-end Deep learning에서 핵심적인 역할을 하게 된다.
- 기존 MIL 기반 WSI survival analysis model들은 패치 간 관계에 따라 서로 다른 network 활용한다.
| cluster-based | Fully-Conneted Networks |
| Graph-based | Graph Convolution Network |
| Sequence-based | Attension-MIL 및 transformer |
- 패치 특징을 패치 간 상관관계에 따라 변환하여 embedding하고,
- embbeding vector를 pooling하여 global feature vector로 변환하여 WSI representation을 추출하게 된다.
(2) Survival Loss Function
- 대부분의 survival analysis model은 hazard function에 대해 특정 가정을 적용한다.
- 대표적인 survival analysis 가정은 다음과 같다.
i) 콕스 비례 위험 모델
ii) 가속 실패 시간 모델
--> 두가지 몬델 전부 simplicity와 interpretability하기 때문에 WIS survival analysis에 널리 사용된다.
- MLE(Maximum Likelihood Estimation) 기반 loss function을 사용하게 되는데,
- 이러한 loss function들은 discriminative model에서 유도되기 때문에,

- point estimation으로 제한되게 된다.
2.2. Adversarial Time-to-Event Analysis
(1) cGAN(Conditional GAN)
- cGAN은 기존에 GAN에 conditional labels을 추가하여 이미지 생성 퀄리티를 향상시킨다.
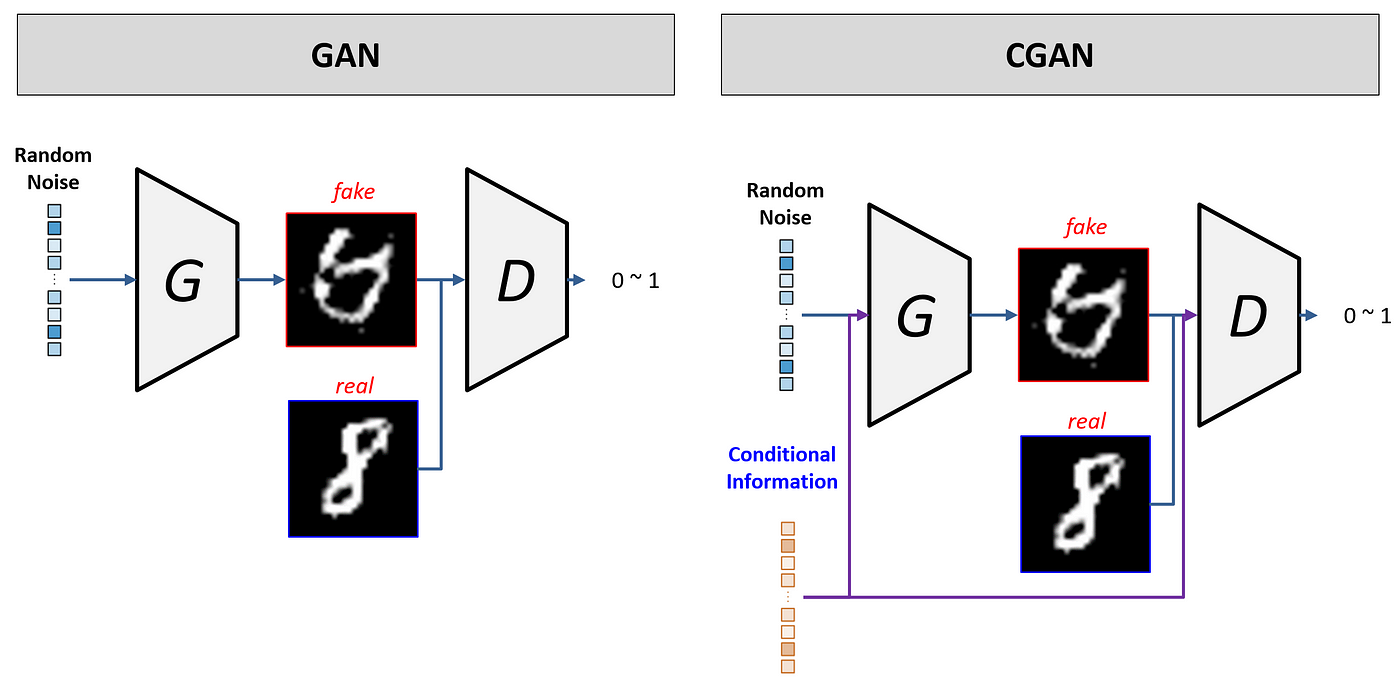
- discriminative model에서 벗어나기 때문에,

- point estimation이 아닌, distribution estimation를 하게 된다.

3. Methodological

3.1. Preliminary
(1) Bag construction for WSIs
- Bag 구성에 두 가지 유형의 패치를 준비한다
i) 특정 구조 없이 개별적인 패치 (generator에서 사용)
ii) 균등한 영역 분할을 기반으로 한 패치(discriminator에서 사용)
- 각 패치에 대해 feature extractor를 적용하여 패치 특징의 bag를 생성한다.

- 이 주어진 X는 generator에서 개별 패치 특징으로 사용될 수 있고,
- discriminator에서 region-wise 패치 특징으로 해석 될 수 있다.
- 이를 통해 survival data를 다음과 같이 정의한다.


- event가 발생한 환자의 데이터는 다음과 같이 정의

- event가 발생하지 않은 환자의 데이터는 다음과 같이 정의

3.2. Adversarial Multiple-Instance Learning
(1) Generator
- Generator는 MIL encoder + MLP(Multi-Layer Perceptron)으로 구성되어 있다.
- 해당 인코더는 global bag representation을 추출하고,
- MLP는 time to event추정을 수행하게 된다.
- 주어진 X에 대해 해당 time-to-event 추정은 다음과 같이 정의된다.


- 해당 방식으로, G는 noise sampling을 통해 시간-사건 Distribution을 암묵적으로 학습할 수 있게 된다.
- 즉, G의 출력 분포가 실제 time-to-event 조건부 분포에 근접하게 학습된다.

- N이 independent variable이기 때문에, joint distribution으로 표현이 가능합니다.
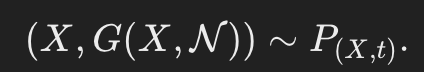
cf) G : cGAN의 최적화 과정을 통해 결정
(2) Discriminator
- Discriminator (D) 는 생성된 가짜 데이터(X,t_hat)과 실제 데이터 (X,t)를 구별하는 역할을 한다.
- 하지만, 기존의 Discriminator는 WSI를 효율적으로 처리하는 데 한계가 존재한다.
- 그 이유는 X가 large Matrix이고, t는 single scalar value이기 때문이다.
- 이를 해결하기 위해, RLIP(Region-level instance projection)기반 Fusion network를 설계하게 된다.
- RLIP는 큰 행렬과 스칼라 값을 결합하는 기법이고,
- RLIP fusion network는 기존 MIL에 추가적인 연산비용을 발생시키지 않다고 한다.
- RILP과정은 다음과 같다.
- 해당 X를 embedding한다.

- 해당 embedding vector를 pooling하여 X_emb 생성한다.(지역 임베딩)

- 생존 시간 t을 MLP를 통해 벡터로 변환시킨다.

- 지역 임베딩 벡터와 시간 임베딩을 결합하여 최종 fusion output을 생성한다.

- region-level embbeding이 output layer에 전달되어 y_region을 생성한다.


- 이 결과를 sigmoid 즉, Logsitic Function에 전달한다.

(3) Network Training
- AdvMIL은 cGAN loss와 Supervision loss를 사용하여 최적화 된다.
i) cGAN loss
- D는 실제 데이터와 가짜 데이터를 구분하도록 최적화
- G는 현실적인 데이터 분포를 따르도록 학습


ii) Supervision loss
- cGAN loss만 사용하면 학습이 어려울 수 있기 때문에 손실함수를 더 추가하였다.

- AdvMIL은 GAN과 유사하게 훈련시킨다고 한다.

3.3. k-fold semi-supervised learning
4. Experiments and results
4.1. Experimental Settings
(1) Dataset Description
- 본 연구에선 세 가지 공개된 WSI dataset을 사용했다고 한다.
i) NLST(National Lung Screening Trial)
ii) Breast Cancer(BRCA)
iii) Low-Grade Glioma(LGG)
- BRCA와 LGG는 TCGA에서 제공된 데이터


(2) Chosen Baselines
- 본 연구에서 네 가지 방법을 기준 모델로 선정하였다.(세가지 MIL범주에서의 대표적 모델들)
1. ABMIL
2. DeepAttnMISL
3. PatchGCN
4. ESAT
- AdvMIL의 효과를 검증하기 위해, 기준 모델을 활용한 세 가지 다른 모델을 비교한다고 한다.

(3) Implementation Details
1. Feature extactor : CLAM(참고)
https://arxiv.org/abs/2004.09666
Data Efficient and Weakly Supervised Computational Pathology on Whole Slide Images
The rapidly emerging field of computational pathology has the potential to enable objective diagnosis, therapeutic response prediction and identification of new morphological features of clinical relevance. However, deep learning-based computational pathol
arxiv.org
- ResNet-50의 Truncated 버전 사용(합성곱층만 사용)

2. Generator
- 각 레이어에서 랜덤 noise를 추가할지 안할지를 binary code(0,1)로 표현
3. Discriminator
- Fusion Network에서 Global Average Pooling Layer을 사용하여 Region Embedding Layer 구현
(4) Evalution Metrics
- C-index : 모델의 risk판별 능력 및 결정 능력 측정
--> classificaiton에서의 AUC와 유사한 역할을 수행
- MAE(Mean Absolute Error)
--> 모델이 예측한 t^과 실제 생존 시간 간의 평균 절대 차이를 계산
- 5 fold cross validation으로 학습 진행

