
0. Reference
https://arxiv.org/abs/1301.3781
Efficient Estimation of Word Representations in Vector Space
We propose two novel model architectures for computing continuous vector representations of words from very large data sets. The quality of these representations is measured in a word similarity task, and the results are compared to the previously best per
arxiv.org
1. Introduction
- 해당 논문의 목표는, 수백만 개의 단어를 포함하는 Vocabulary에서 저차원의 고품질의 word vector를 얻는것이다.
- 즉, Onehot-vector로 표현하는 것이 아닌, Continuous word representations으로 나타낸다는 것을 의미한다.
- 해당 논문에선, word2vec을 통해, 의미가 유사한 단어들은 vector space에서 서로 가까이 위치해있다는것뿐만 아니라,
- 단어 간 유사성도 표현이 가능하다고 한다.
- 다음과 같은 예시가 있다.
"""
vector("king") - vector("man") + Vector("Woman") ==?

- 이 결과의 벡터가 여기서 Queen 벡터와 가장 가깝기에 Queen벡터를 답으로 내뱉었다고 한다.
"""
2. Model Architectures
- 본 논문에선 neural Network을 활용하여 학습된 distributed representation에 집중한다.
- 여기서 Distributed Representaton은 비슷한 아이들은 비슷한 분포를 보일 것이라는 주장이라고 생각하면 된다.
2.1. NNLM(Feedforward Newral Net Language Model, NNLM)
- 해당 모델은 네가지의 layer로 구성되어 있다.

1. input layer
2. Projection layer
3. Hidden layer
4. Output layer
- input layer에서는 이전 N개의 단어를 받아들인다. 각 단어는 1 of V(one-hot) encoding으로 표현되며,
- 여기서, V는 사전에 들어있는 단어의 개수를 의미한다.
- 이 input vector는 projection matrix를 통해 projection layer로 mapping된다.
- (이떄 나오게 된 verctor을 embedding vector라한다.)

- 해당 layer의 차원은 N x D이며, D는 word vector의 차원을 의미한다.(위 사진에선 M과 D는 동일)
- 이 과정에서 느껴지는게 있겠지만, one-hot vector를 넣어주기 때문에, 딱 빨간색 M개만 계산된다는 것을 알 수 있다.
- 즉, 계산량이 적다는 것이다.
- 그래서, 각각의 one hot vector를 계산한 output들을 그대로 concat해준다.

- 하지만 그 다음 hidden layer부터 계산량이 증가하게 된다.
- 그 이유는 Projection layer의 output은 dense vector이기 때문이다.
- 그래서 계산량은 NxDxH가 되고,
- 마지막 Output layer는 단어를 return해야하기 때문에 one-hot vector로 반환해야한다.(probability vector를 통해 얻을 수 있음)
- 즉 계산량은 H x V가 된다.
- 그러면 한개의 샘플당 모델의 전체 복잡도는 다음과 같다.
- Q = N x D + N x D x H + H x V
- 여기서 V는 매우 클 수밖에 없다. 따라서, 해당 모델은 매우 부담이 되게 된다.
- 해당 문제를 해결하기 위해서 다음과 같은 solution이 나오게 되었다.
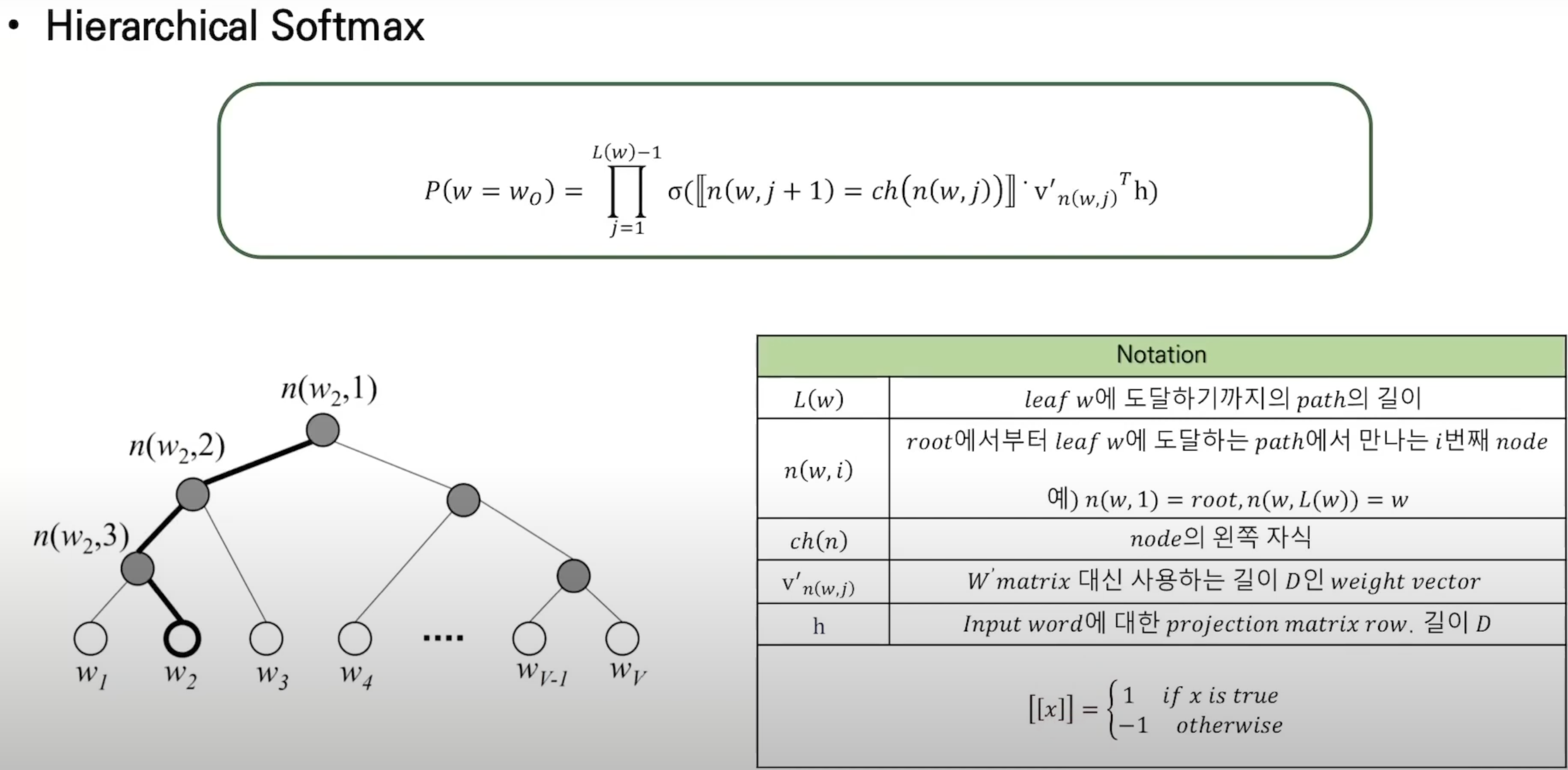
i) Hierarchical Softmax
ii) Huffman Tree --> 빈도가 클수록 depth가 짧음
- 뒤에서 자세히 잡아갈 것이다.
3. Word2Vec
- 즉, 해당 논문의 목적은 다음과 같다.
- Distributed Representation을 보다 효율적으로 학습하기 위해, 계산 복잡도를 최소화 하는 것이다.
- 해당 논문에선 새로운 두 가지 모델을 제안한다.
i) CBOW(Continuos Bag-of-Words Model)
ii) Skip-gram(Continuos Skip-gram Model)
- 해당 논문에서, 가장 큰 게산 복잡도를 유발하는 요소는 non-lieanr hidden layer라고 한다.
- 신경망에서 non-linear layer는 강력한 representation을 제공하는 요소이기도 하지만,
- 이러한 장점을 일부 포기하고, 훨씬 더 많은 데이터를 효율적으로 학습할 수 있는 단순한 모델을 찾고자 하였다고 한다.
- 새로운 모델은 NNLM을 다음 두 단계로 학습하는 전략으로 진행되었다고 한다.
"""
i) 단순한 모델을 사용해 continuos word vectors를 먼저 학습
ii) 그 후, 이 벡터를 기반으로 N-gram 기반 NLM을 학습
- 여기서 N-gram이란 문장에서 N개의 단어를 묶는다는 것을 의미한다.(Window size = N)
"""
3.1. CBOW
- Feedforward NNLM과 유사하지만, 다음과 같은 차이점이 존재한다.
i) non-linear hidden layer가 제거
ii) Projection layer가 모든 단어에 대해 공유된다.

- 이 구조에서 단어들은 각 동일한 위치로 투사되기에, word vector들이 평균화되게 된다.
- 기존의 Bag of words와는 달리, 과거와 미래의 단어를 통해 현재의 단어를 예측하는 방식으로 진행된다.
- 이를 예측(classify)하기 위해 log-lienar classifier로 작동된다고 한다.
- 이 모델의 학습 복잡도는 다음과 같다.
Q = N x D + D x log_2(V) (log_2(V)인 이유는 hierarchical softmax때문(뒤에서설명))
3.2. Skip-gram
- CBOW와 구조적으로 유사하지만, 예측 방향이 반대다.
- CBOW같은 경우, 문맥을 통해 현재 단어를 예측하고자 헀다면,
- Skip-gram은 현재 단어를 통해 문맥의 단어를 예측하고자 하였다.
- 즉, Skip-gram은 문장에서의 다른 단어 하나를 기반으로,
- 해당 단어 주변에 있는 단어들을 정확히 classify하도록 학습하는 모델이다.


4. Hierarchical Softmax

'Paper Review(논문 리뷰) > NLP' 카테고리의 다른 글
| [논문 리뷰] [NLP] Evaluation methods for unsupervised word embeddings (0) | 2025.03.30 |
|---|---|
| [논문 리뷰] [NLP] glove: global vectors for word representation (1) | 2025.03.30 |
| [논문 리뷰] [NLP] Distributed Representations of Words and Phrasesand their Compositionality (1) | 2025.03.29 |
| [논문 리뷰] [NLP] End-To-End Memory Networks (0) | 2025.02.23 |