
1.Introduce
- 해당 챕터에서는 R에서 데이터를 일관성있게 정리하는 법을 학습한다.
- 이는 타이디(tidy,깔끔한) 데이터 라는 구조이다.
- 타이디 데이터에 대해 실무적으로 소개하고, tidyr 패키지에 포함된 도구를 살펴본다
1.1.Ready
- 지저분한 데이터셋을 정리하는 도구가 있는 tidyr 패키지에 중점을 둔다.
- tidyr 은 tidyverse의 핵심 구성원이다.
2.타이디 데이터
- 하나의 기본 데이터를 표현하는 방식은 다양하다.
- 다음 예시는 같은 데이터를 다른 네 가지 방식으로 구성하여 보여준다.
- 각 데이터셋은 네 개의 변수, country,year,population 및 cases의 값을 동일하게 보여주지만 다른 방식으로 구성한다.
table1
# A tibble: 6 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583table2
# A tibble: 12 × 4
country year type count
<chr> <dbl> <chr> <dbl>
1 Afghanistan 1999 cases 745
2 Afghanistan 1999 population 19987071
3 Afghanistan 2000 cases 2666
4 Afghanistan 2000 population 20595360
5 Brazil 1999 cases 37737
6 Brazil 1999 population 172006362
7 Brazil 2000 cases 80488
8 Brazil 2000 population 174504898
9 China 1999 cases 212258
10 China 1999 population 1272915272
11 China 2000 cases 213766
12 China 2000 population 1280428583 table3
# A tibble: 6 × 3
country year rate
<chr> <dbl> <chr>
1 Afghanistan 1999 745/19987071
2 Afghanistan 2000 2666/20595360
3 Brazil 1999 37737/172006362
4 Brazil 2000 80488/174504898
5 China 1999 212258/1272915272
6 China 2000 213766/1280428583table4a
# A tibble: 3 × 3
country `1999` `2000`
<chr> <dbl> <dbl>
1 Afghanistan 745 2666
2 Brazil 37737 80488
3 China 212258 213766table4b
# A tibble: 3 × 3
country `1999` `2000`
<chr> <dbl> <dbl>
1 Afghanistan 19987071 20595360
2 Brazil 172006362 174504898
3 China 1272915272 1280428583- 이들은 모두 같은 데이터를 표현하지만, 사용성이 같지는 않다.
- 데이터셋을 타이디하게 만드는, 서로 연관된 세 가지 규칙은 다음과 같다.
1. 변수마다 해당되는 열이 있어야 한다.
2. 관측값마다 해당되는 행이 있어야 한다.
2. 값마다 해당하는하나의 셀이 있어야한다.

- 세 가지 규칙은 서로 연관되어 있음
- 이 셋 중 두 가지만 충족시키는 것은 불가능함
- 이 상호관계 때문에 다음의 더 간단하고 실용적인 지침이 도출된다.
1. 데이터셋을 티블에 각각 넣어라.
2. 변수를 열에 각각 넣어라.
- 위의 5가지 예시중 table1만 타이디하다.
- 해당 테이블만 유일하게 각 열이 변수인 표현이기 때문이다.
- 데이터가 타이디해야 하는 이유가 뭘까?
- 주요 장점은 두가지가 존재한다.
I) 타이디 데이터를 사용하면 이에 적용할 도구들이 공통성을 가지게 되어, 이들을 익히기 더 쉬워진다.
II)변수를 열에 배치하면 R의 벡터화 속성이 가장 발휘된다는 점에서 구체적인 장점이 생김
- table1 즉 타이디데이터를 사용하여 작업하는 방법을 보여주는 몇가지 간단한 예제
#10,000명 당 비율 계산
> table1 %>%
+ mutate(rate = cases / population * 10000)
# A tibble: 6 × 5
country year cases population rate
<chr> <dbl> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071 0.373
2 Afghanistan 2000 2666 20595360 1.29
3 Brazil 1999 37737 172006362 2.19
4 Brazil 2000 80488 174504898 4.61
5 China 1999 212258 1272915272 1.67
6 China 2000 213766 1280428583 1.67 #연간 사례 수 계산
> table1 %>%
+ count(year, wt = cases)
# A tibble: 2 × 2
year n
<dbl> <dbl>
1 1999 250740
2 2000 296920#시간에 따른 변화 시각화
> library(ggplot2)
> ggplot(table1, aes(year,cases)) +
+ geom_line(aes(group = country), color = "grey") +
+ geom_point(aes(color = country))
2.1. 연습문제
Q1) 변수와 관측값이 각 샘플 테이블에서 어떻게 구성되어 있는지 설명하라.
I) table1
table1
# A tibble: 6 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583- 각 행은 country, year의 조합을 나타내고
- 각 열은 cases 에따른 population을 나타낸다.
II) table2
table2
# A tibble: 12 × 4
country year type count
<chr> <dbl> <chr> <dbl>
1 Afghanistan 1999 cases 745
2 Afghanistan 1999 population 19987071
3 Afghanistan 2000 cases 2666
4 Afghanistan 2000 population 20595360
5 Brazil 1999 cases 37737
6 Brazil 1999 population 172006362
7 Brazil 2000 cases 80488
8 Brazil 2000 population 174504898
9 China 1999 cases 212258
10 China 1999 population 1272915272
11 China 2000 cases 213766
12 China 2000 population 1280428583- 각 행은 country, year, type의 조합을 나타내고
- 각 열은 count를 의미한다.
III) table3
table3
# A tibble: 6 × 3
country year rate
<chr> <dbl> <chr>
1 Afghanistan 1999 745/19987071
2 Afghanistan 2000 2666/20595360
3 Brazil 1999 37737/172006362
4 Brazil 2000 80488/174504898
5 China 1999 212258/1272915272
6 China 2000 213766/1280428583
>- 각 행은 country,year의 조합을 의미하고
- 각 열은 해당 rate를 의미한다.
3.피봇하기
- 우리가 마주치게 될 대부분의 데이터들은 타이디하지 않을 것이다.
- 이유는 크게 두가지가 존재한다.
I) 대부분의 사람들은 타이디 데이터의 원리에 익숙하지 않으며, 데이터 작업에 많은 시간을 써야한다.
II) 데이터는 분석보다는 다른 용도에 편리하도록 구성되는 경우가 많다.
- 따라서 실제 분석에서는 타이디하게 만드는 작업이 필요하다.
- 첫 번째 단계에서는 항상 변수와 관측값이 무엇인지 파악하는 것이다.
- 두 번째 단계에서는 자주 일어나는 다음의 두 가지 문제 중 하나를 해결하는 것
I) 하나의 변수가 여러 열에 분산되어 있을 수 있다.
II) 하나의 관측값이 여러 행에 흩어져 있을 수 있다.
- 일반적으로 한 데이터셋은 이 문제들 중 하나로 인해 어려움을 겪게 된다.
- 정말 운이 없는 경우만, 두 문제 모두로 고생하게 될 것이다.
- 이러한 문제를 해결하기위해선 tidyr에서 가장 중요한 함수인 pivot_longer()과 pivit_wider()가 필요.
3.1. 더 길게 만들기
- 자주 생기는 문제는 데이터셋의 일부 열 이름이 변수 이름이 아니라 변수 값인 경우이다.
-table4a를 보면 열 이름 1999와 2000은 year 변수 값을 나타내며, 각 행은 하나가 아닌 두 개의 관측값을 나타낸다.
table4a
# A tibble: 3 × 3
country `1999` `2000`
<chr> <dbl> <dbl>
1 Afghanistan 745 2666
2 Brazil 37737 80488
3 China 212258 213766
>-해당 데이터셋을 타이디하게 만들려면 해당 열을 새로운 두 변수로 피봇해야한다.
- 이 작업을 설명하기 위해 세 가지 파라미터가 필요하다.
i) 변수가 아니라 값을 나타내는 열 집합. 이 예에서는 열 1999와 열 2000이다.
ii) 열 이름 자리에 나타난 값의 변수 이름. 여기에서는 year이다.
iii) 셀에 값이 분산되어 있는 변수의 이름. 여기에서는 cases이다.
이러한 파라미터와 함께 pivot_longer() 호출을 생성할 수 있다.
> table4a %>%
+ pivot_longer(c(`1999`,`2000`),names_to = 'year',values_to = 'cases')
# A tibble: 6 × 3
country year cases
<chr> <chr> <dbl>
1 Afghanistan 1999 745
2 Afghanistan 2000 2666
3 Brazil 1999 37737
4 Brazil 2000 80488
5 China 1999 212258
6 China 2000 213766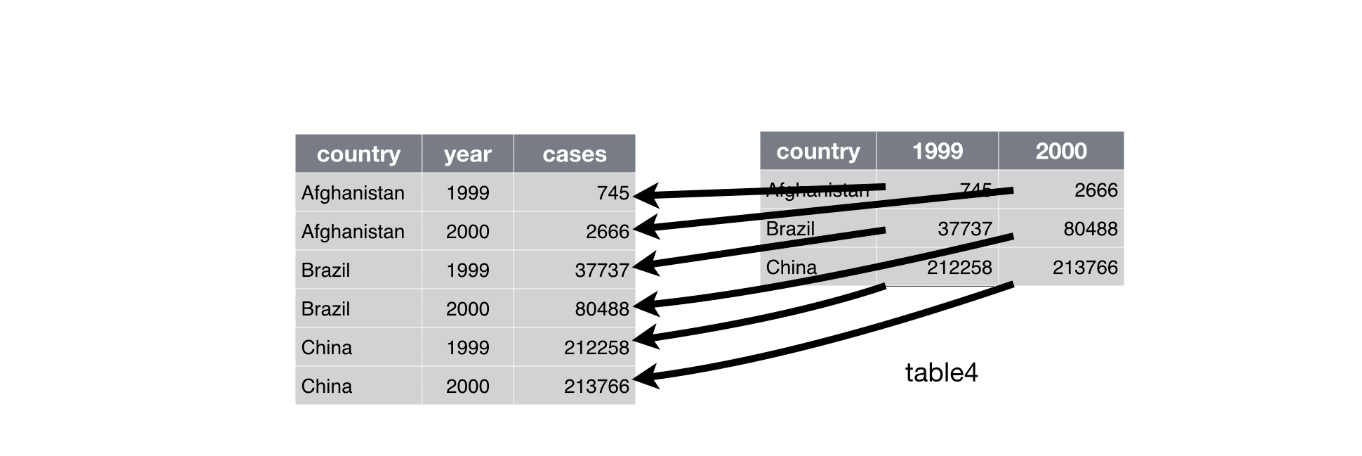
3.2. 더 넓게 만들기
- pivot_wider()는 pivor_longer()의 반대이다. 관측값이 여러행에 흩어져 있을 때 사용한다.
- 예를 들어 table2를 보자. 하나의 관측값은 한 해, 한 국가에 대한 것이지만 각 관측값이 두 행에 흩어져 있다.
> table2
# A tibble: 12 × 4
country year type count
<chr> <dbl> <chr> <dbl>
1 Afghanistan 1999 cases 745
2 Afghanistan 1999 population 19987071
3 Afghanistan 2000 cases 2666
4 Afghanistan 2000 population 20595360
5 Brazil 1999 cases 37737
6 Brazil 1999 population 172006362
7 Brazil 2000 cases 80488
8 Brazil 2000 population 174504898
9 China 1999 cases 212258
10 China 1999 population 1272915272
11 China 2000 cases 213766
12 China 2000 population 1280428583- 이것을 타이디하게 하기 위해,먼저 pivot_longer()와 비슷한 방식으로 표현 방법을 분석한다.
-그러나 이번에는 파라미터가 두 개만 필요하다.
i) 변수 이름을 포함하는 열, 여기에선 type
ii) 값을 포함하는 열, 여기에서는 count
table2 %>%
+ pivot_wider(names_from = type, values_from = count)
# A tibble: 6 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583
'DS Study > R4DS(R언어)' 카테고리의 다른 글
| [R4DS] [5] readr로 하는 데이터 불러오기 (1) | 2024.04.05 |
|---|---|
| [R4DS] [4] tibble로 하는 티블 (0) | 2024.04.04 |
| [R4DS] [3-3] 공변동 (0) | 2024.04.03 |
| [R4DS] [3-2] 결측값 (0) | 2024.04.03 |
| [R4DS] [3-1] 탐색적 데이터 분석(EDA) (0) | 2024.04.01 |