
1. facet
- https://ceulkun04.tistory.com/6
[R언어] [2] 심미성 매핑
1. 심미성 매핑 "그래프의 가장 큰 가치는 전혀 예상하지 못한 것을 보여줄 때이다." - 죤 튜키 https://ceulkun04.tistory.com/5 (R언어 [1] 강에서 displ과 hwy의 연관성을 비교해서 나타낸 산점도를 다시보자
ceulkun04.tistory.com
- 2장에선 변수를 추가하는 방법으로 심미성을 이용하는 방법에 대해 알아보았다.
- 또 다른 변수 추가 방법을 소개하고자 한다.
- 범주형 변수에 특히 유용한 방법 -> 플롯을 면분할(Facet)으로 나누는 것
2. facet_wrap() #하나의 변수
- facet_wrap()의 첫 번째 인수로는 ~와 뒤에 변수 이름이 따라오는 공식(formula)이어야 함
- facet_wrap()에 전달하는 변수는 이산형이어야한다.
- ex)
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_wrap(~class, nrow = 3)
facet_wrap(~class, nrow = 3)
# ~class : class를 기준으로 분리
# nrow = 3 : 행을 3개로 분리3.facet_grid() #두 변수 조합
- facet_grid()의 첫 번째 인수도 정형화되어 있다.
- facet_grid('행을 구분할 인수' ~ '열을 구분할 인수')
-ex)
> ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy), color = 'blue') +
facet_grid(drv ~ cyl)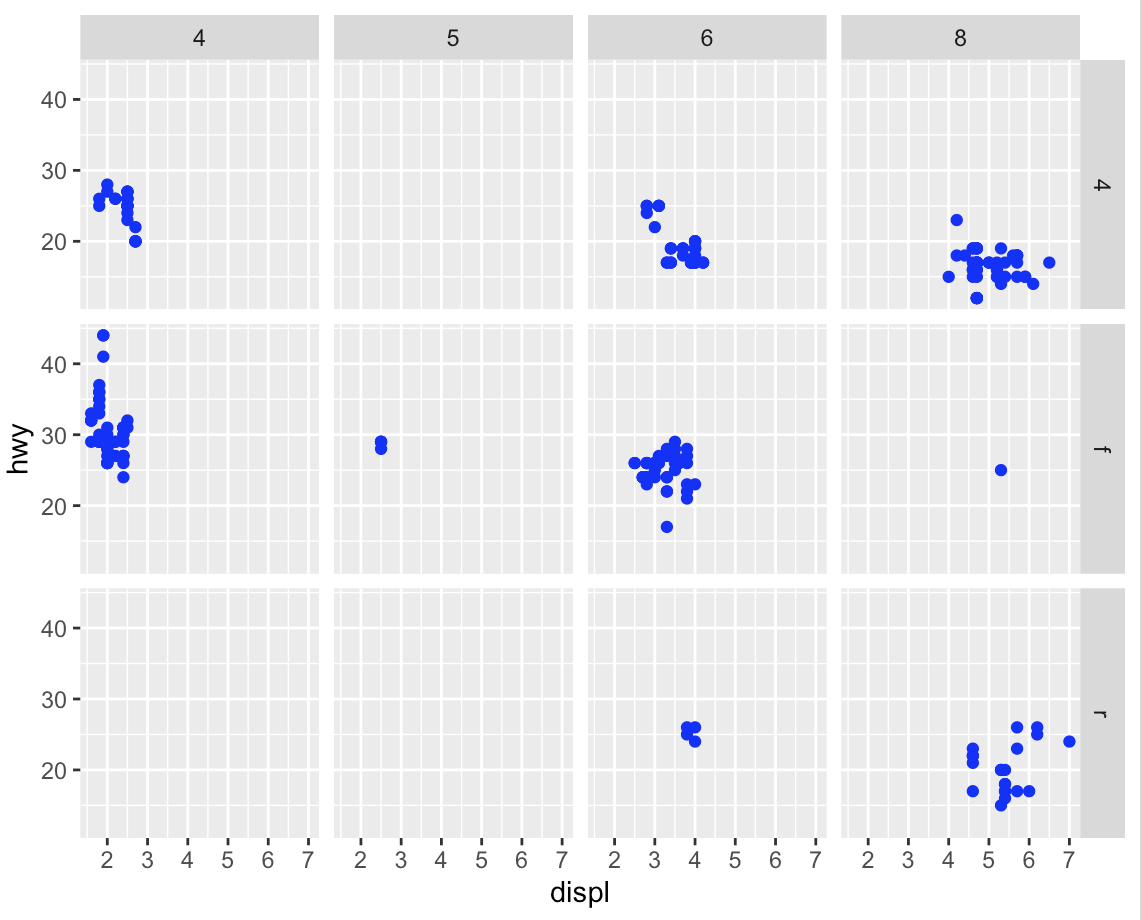
- 열이나 행으로 면분할하고 싶지 않다면 변수 이름 대신 .을 이용하면 됨.
ex)
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_wrap(drv ~ .)
4. 연습문제
Q1) 연속형 변수로 면분할하면 어떻게 되는가?
- mpg dataset에 존재하는 연속형 변수는 3가지
----> displ, hwy, cty
- code :
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_wrap(~cty, nrow = 2)

--면분할은 가능하지만 연속하는 값들마다 분리되기에 의미있진 않다.
Q2) facet_grid(drv ~ cyl)로 만든 플롯에 있는 빈 셀들은 무엇을 의미하는가? 다음의 플롯과 어떻게 연관되는가
- 다음의 플롯 :
ggplot(data = mpg) +
geom_point(mapping = aes(x = drv , y = cyl))- facet_grid로 만든 플롯에 있는 빈 셀들은 해당되는 data가 없음을 의미한다.
- 밑의 Plot은 다음의 플롯을 보여준다.
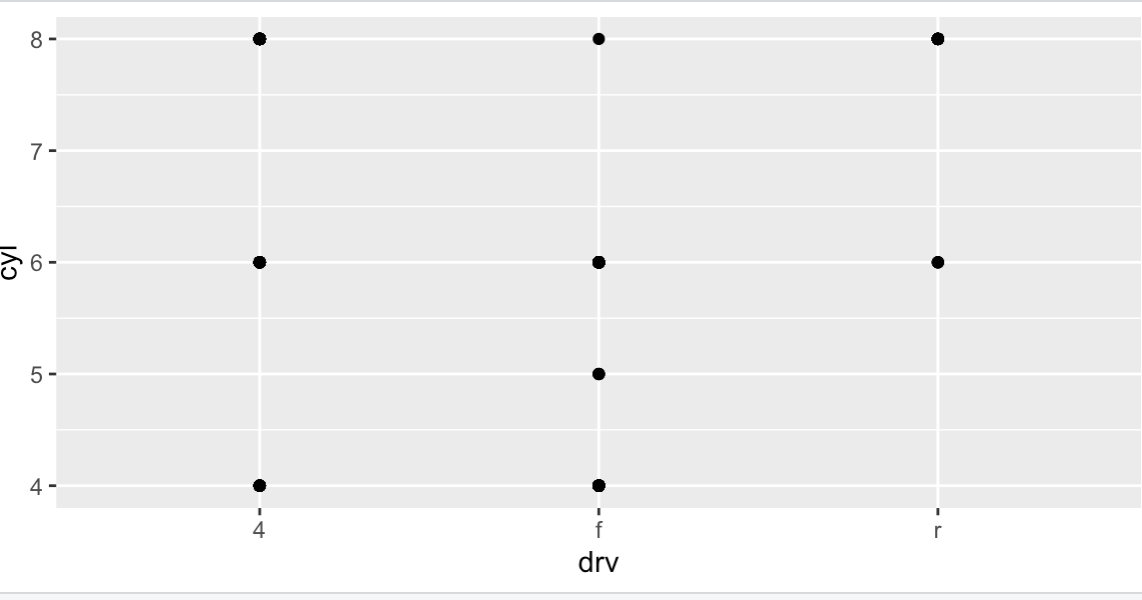
- 해당 플롯도 마찬가지로 비어있는 데이터 즉(4,5) , (r,5)를 보여준다는 점이 연관되어 있다.
Q3) 다음의 코드는 어떤 플롯을 만드는가? .은 어떤 역할을 하는가?
# 1번 코드
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_wrap(drv ~ .)
# 2번 코드
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_grid(.~cyl)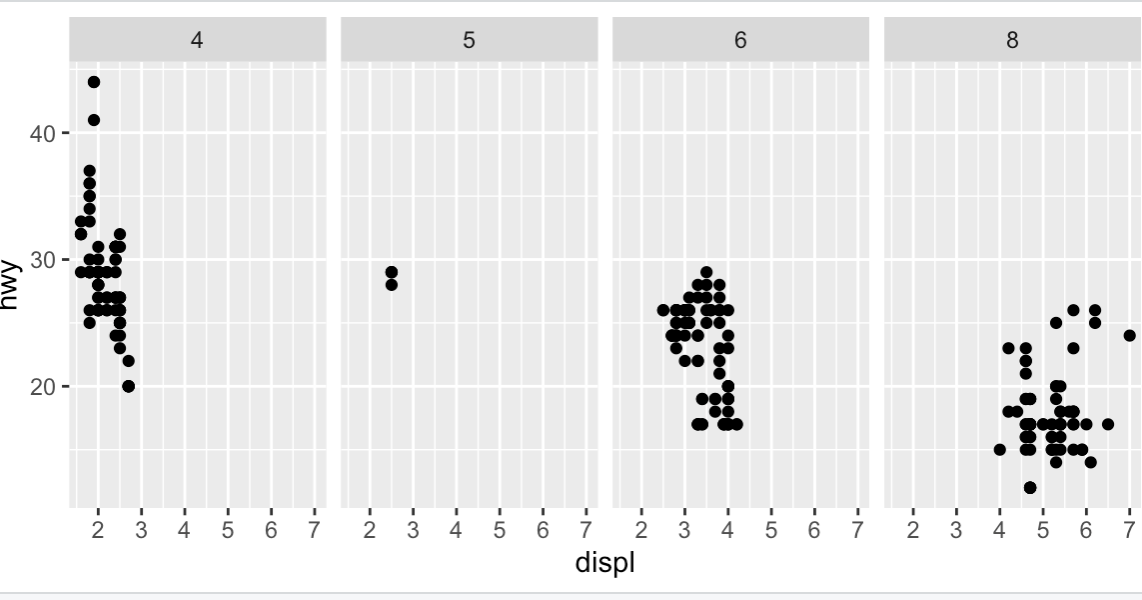
- 해당 플롯들을 보면 알수있듯 하나의 열 or 하나의 행으로 분할하고 싶을 때 '.'을 활용할수있다.
Q4) 이 절의 면분할된 첫 번째 플롯을 살펴보라. Q4-1)색상 심미성을 쓰지 않고 면분할하면 어떤 이점이 있는가? Q4-2)단점은 무엇인가?
Q4-3)데이터가 더 크다면 이 균형은 어떻게 바뀌겠는가?
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_wrap(~ class , nrow = 2)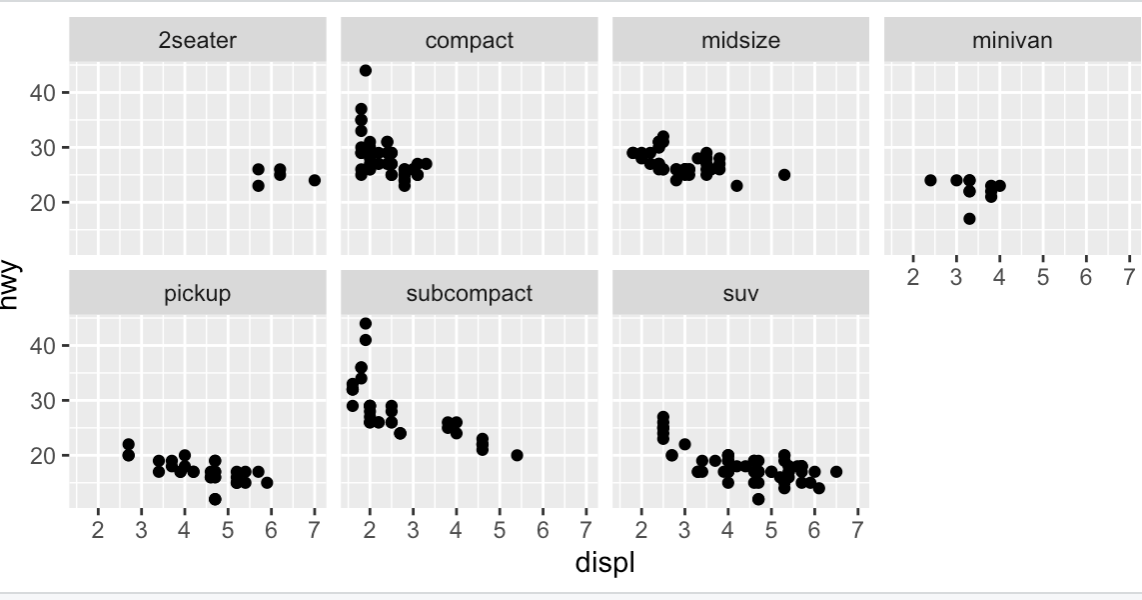
- Q4-1) 색상 심미성을 쓰지 않고 면분할을 하면 생기는 이점은 class의 종류에 따라 displ,hwy의 연관성이 한눈에 들어오게 된다.
- Q4-2) 각각의 class에 대해서 개별적으로 분석하긴 쉽지만 각 class를 비교할 때 어려움을 느낀다.
- Q4-3) 데이터가 더 크다면 각각의 class에 대한 분석이 더욱 한눈에 들어올듯하다.
Q5) ?facet_wrap을 읽어라. Q5-1) nrow의 역할은 무엇인가? Q5-2)ncol의 역할은 무엇인가? Q5-3)개별 패널의 배치를 조정할 수 있는 다른 방법은 무엇인가? Q5-4) facet_grid()에는 nrow, ncol 인수가 왜 없는가?
Q5-1) nrow : 행의 개수를 결정해준다.
Q5-2) ncol : 열의 개수를 결정해준다.
Q5-3) 개별 패널의 배치를 조정할 수 있는 다른 방법 : facet_grid() 함수를 사용하여 행 및 열을 특정 변수로 분할하여 패널 생성 가능
- scales 매개변수를 사용하여 각 패널의 축 스케일을 독립적으로 조정할 수도 있음
Q5-4) facet_grid()에서는 행,열을 특정 변수에 따라 분리하기 때문.
'DS Study > R4DS(R언어)' 카테고리의 다른 글
| [R4DS] [1-6] 위치 조정 (0) | 2024.03.30 |
|---|---|
| [R4DS] [1-5] 통계적 변환 (0) | 2024.03.30 |
| [R4DS] [1-4] 기하 객체 (Geom 함수 정리) (0) | 2024.03.30 |
| [R4DS] [1-2] 심미성 매핑 (0) | 2024.03.27 |
| [R4DS] [1-1] ggplot2 이란? (2) | 2024.03.27 |