
1. Bias / Variance

- 다음과 같이 같은 데이터셋이 3개가 있다고 생각해보자.
- Regression Problem을 푼다고 생각했을 때 다음과 같이 3개로 나타낸다고 생각해보자.
- 첫번째 : 일차함수 , 두번째 : 이차함수, 세번째 : 오차함수

- 우리는 이중에 가장 적합하다고 생각하는 건 아마 두번째 그림이 가장 잘 설명한다고 생각할 것이다.
- 첫번째 일차함수 같은 경우 데이터를 덜 설명하게 된다. 이를 Under fitting이라고 한다.(High bias를 가진다.)
- 세번째 오차함수 같은 경우 데이터를 과하게 설명하게 된다. 이를 Over Fitting이라고 한다.(HIgh Variance를 가진다.)
2. Regularization
- Overfitting을 방지하기 위해 나오게 된 기법인데
- Stanford강의에선 L2 Regularization을 설명한다.
- 간단하게 기존의 Loss Function에 Regularization을 더해주면 된다. (이걸 Minimization하면 된다.)

- lambda를 0이라고 뒀을때 regression한 모습을 확인해보자.

- 여기서 lambda에 수치를 부여해주면 과하게 fitting되었던게 조금 느슨해지게 된다.

- 즉, Variance를 낮추고 데이터를 느슨하게 맞추는 역할을 하게 된다.
- 과하게 lambda에 수치를 부여하면 Underfitting된다.

- 여기서 우리는 SVM이 왜 Overfitting이 될 가능성이 적은지를 알 수 있다.
- SVM은 다음을 minimize하는 것과 같다.
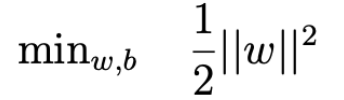
- 마치 L2 Regularizaiton과 비슷하기 때문에 Overfitting을 억제시켜준다.
3. Model Complexity와 Overfitting과의 관계

- 모델이 복잡하면 복잡할수록 Train Data는 error가 계속 감소하지만,
- Test Data는 error가 줄다가 늘어나는 모습을 볼 수 있다.
- 즉, Model Complexity가 늘어나면 늘어날수록 데이터에 더 fitting된다는 의미이다.
4. Data Splits
- 우리는 모델을 학습시키기 위해 Data를 Train/validation/test 로 나누게 된다.
- 더 자세히 알아보자.
4.1. Hold-out validation
- 다음과 같이 딱 한번 데이터를 Train/validation/test로 나누는 방식을 의미한다.

- 보통 Validation set 과 Test set의 크기는 동일하게 두는게 좋다.
-각각의 Data set이 하는 역할은 다음과 같다.
"""
1) Train set
- 어떤 모델을 적용할 것인가, 어떻게 구조를 작설할것인가를 결정하게 된다.
- 가설을 세운다는 의미를 갖는다.
2) Validation set
- Hyperparameter tuning을 하게 된다.
- 좀 더 error가 가장 작은 쪽으로 조정한다고 생각하면 된다.
3) Test set
- Model의 성능을 평가하는 Data set이 된다.
"""
4.2. K-fold Cross Validation
- 데이터셋이 적을때 k-fold cross validation을 사용하는 것도 좋다고 한다.
- 밑의 그림과 같이 test를 제외한 train을 K개로 나누고 각 조각마다 val set으로 두어 계속 튜닝하게 된다.
- 그리고 결과적으로 나오게 되는 parameter를 가지고 test set을 돌려 성능을 평가한다.
- 보통 k = 10 이라고 둔다고 한다.

- Deep Learning을 학습시킬 땐 K-fold Validation을 사용하는건 그렇게 의미있지 않다고 한다.
- 이에 대해 교수가 말하길 애초에 딥러닝모델을 학습시키는데 오래걸리기도 하고,
- 딥러닝의 본질적인 원리 때문에 k-fold validation을 사용하는 것보단,
- 입력 데이터의 feature를 수정하거나, transfer learning이라든가 이런 방향으로 제시한다고 한다.
'DS Study > CS 229(Machine Learning)' 카테고리의 다른 글
| [CS229] [10] Lecture 10 - Decision Trees and Ensemble Methods (0) | 2025.02.07 |
|---|---|
| [CS229] [9] Lecture 9 - Approx/Estimation Error & ERM (1) | 2025.02.07 |
| [CS229] [7] Lecture 7 - Kernels (2) | 2025.01.22 |
| [CS 229] [6] Lecture 6 - Support Vector Machines (1) | 2025.01.20 |
| [CS229] [5] Lecture 5 - GDA & Naive Bayes (0) | 2025.01.17 |
1. Bias / Variance
- 다음과 같이 같은 데이터셋이 3개가 있다고 생각해보자.
- Regression Problem을 푼다고 생각했을 때 다음과 같이 3개로 나타낸다고 생각해보자.
- 첫번째 : 일차함수 , 두번째 : 이차함수, 세번째 : 오차함수
- 우리는 이중에 가장 적합하다고 생각하는 건 아마 두번째 그림이 가장 잘 설명한다고 생각할 것이다.
- 첫번째 일차함수 같은 경우 데이터를 덜 설명하게 된다. 이를 Under fitting이라고 한다.(High bias를 가진다.)
- 세번째 오차함수 같은 경우 데이터를 과하게 설명하게 된다. 이를 Over Fitting이라고 한다.(HIgh Variance를 가진다.)
2. Regularization
- Overfitting을 방지하기 위해 나오게 된 기법인데
- Stanford강의에선 L2 Regularization을 설명한다.
- 간단하게 기존의 Loss Function에 Regularization을 더해주면 된다. (이걸 Minimization하면 된다.)
- lambda를 0이라고 뒀을때 regression한 모습을 확인해보자.
- 여기서 lambda에 수치를 부여해주면 과하게 fitting되었던게 조금 느슨해지게 된다.
- 즉, Variance를 낮추고 데이터를 느슨하게 맞추는 역할을 하게 된다.
- 과하게 lambda에 수치를 부여하면 Underfitting된다.
- 여기서 우리는 SVM이 왜 Overfitting이 될 가능성이 적은지를 알 수 있다.
- SVM은 다음을 minimize하는 것과 같다.
- 마치 L2 Regularizaiton과 비슷하기 때문에 Overfitting을 억제시켜준다.
3. Model Complexity와 Overfitting과의 관계
- 모델이 복잡하면 복잡할수록 Train Data는 error가 계속 감소하지만,
- Test Data는 error가 줄다가 늘어나는 모습을 볼 수 있다.
- 즉, Model Complexity가 늘어나면 늘어날수록 데이터에 더 fitting된다는 의미이다.
4. Data Splits
- 우리는 모델을 학습시키기 위해 Data를 Train/validation/test 로 나누게 된다.
- 더 자세히 알아보자.
4.1. Hold-out validation
- 다음과 같이 딱 한번 데이터를 Train/validation/test로 나누는 방식을 의미한다.
- 보통 Validation set 과 Test set의 크기는 동일하게 두는게 좋다.
-각각의 Data set이 하는 역할은 다음과 같다.
"""
1) Train set
- 어떤 모델을 적용할 것인가, 어떻게 구조를 작설할것인가를 결정하게 된다.
- 가설을 세운다는 의미를 갖는다.
2) Validation set
- Hyperparameter tuning을 하게 된다.
- 좀 더 error가 가장 작은 쪽으로 조정한다고 생각하면 된다.
3) Test set
- Model의 성능을 평가하는 Data set이 된다.
"""
4.2. K-fold Cross Validation
- 데이터셋이 적을때 k-fold cross validation을 사용하는 것도 좋다고 한다.
- 밑의 그림과 같이 test를 제외한 train을 K개로 나누고 각 조각마다 val set으로 두어 계속 튜닝하게 된다.
- 그리고 결과적으로 나오게 되는 parameter를 가지고 test set을 돌려 성능을 평가한다.
- 보통 k = 10 이라고 둔다고 한다.
- Deep Learning을 학습시킬 땐 K-fold Validation을 사용하는건 그렇게 의미있지 않다고 한다.
- 이에 대해 교수가 말하길 애초에 딥러닝모델을 학습시키는데 오래걸리기도 하고,
- 딥러닝의 본질적인 원리 때문에 k-fold validation을 사용하는 것보단,
- 입력 데이터의 feature를 수정하거나, transfer learning이라든가 이런 방향으로 제시한다고 한다.
'DS Study > CS 229(Machine Learning)' 카테고리의 다른 글
| [CS229] [10] Lecture 10 - Decision Trees and Ensemble Methods (0) | 2025.02.07 |
|---|---|
| [CS229] [9] Lecture 9 - Approx/Estimation Error & ERM (1) | 2025.02.07 |
| [CS229] [7] Lecture 7 - Kernels (2) | 2025.01.22 |
| [CS 229] [6] Lecture 6 - Support Vector Machines (1) | 2025.01.20 |
| [CS229] [5] Lecture 5 - GDA & Naive Bayes (0) | 2025.01.17 |