
0. Reference
https://arxiv.org/abs/1412.3555
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
In this paper we compare different types of recurrent units in recurrent neural networks (RNNs). Especially, we focus on more sophisticated units that implement a gating mechanism, such as a long short-term memory (LSTM) unit and a recently proposed gated
arxiv.org
1. Introduction
- RNN은 최근 여러 머신러닝 작업에서 유의미한 성과를 보이고 있다.
- 특히, 입출력의 길이가 가변적인 경우 효과적이다.
- 본 논문에선 LSTM, GRU, tanh model 세개의 모델에 대해서 평가하였다고 한다.
2. Background : Recurrent Neural Network
- RNN은 기존의 feedforward neural network를 확장한 형태로, 가변 길이의 시퀀스를 처리할 수 있는 신경망이다.
- RNN은 매 시점의 활성화 상태가 이전 시점의 활성화 상태에 의존하는 순환 상태를 가짐으로써 가변 길이의 시퀀스를 처리할 수있다.
- 수식으로 나타내면 다음과 같이 업데이트를 한다는 걸 알 수 있다.
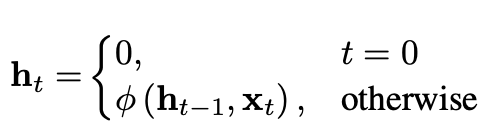
- 여기서 phi는 nonlinear function이다.
- 조금더 일반화하자면 다음과 같다.
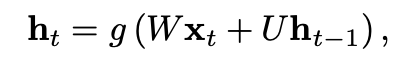
- generative RNN은 주어진 state h_t에 대하여 sequence의 다음 element에 대한 확률분포를 생성한다.
- 그 Sequence Proability는 다음과 같이 decompose된다
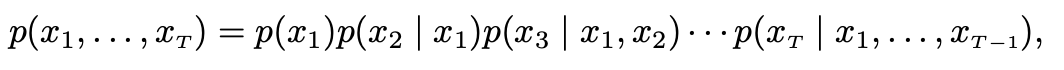
- 여기서 마지막 element는 sequence의 끝을 나타내는 특수한 값이다. 각 조건부 확률 분포를 다음과 같이 모델링 시킬 수 있다.
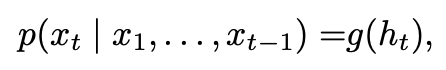
- 이러한 generative RNN이 본 논문의 주제라고 한다.
- 여기서, 길이가 긴 Input이 들어오게 되면 RNN은 long-term dependencies를 포착하도록 학습하기 어렵기 때문에,
- gradient vanish나 gradient explode가 발생하게 된다.
- 이러한 문제를 해결하기위해서 두 가지 방식으로 시도했다고 하는데,
- 첫번짼 SGD가 아닌 다른 Optimization을 사용하는 것이고,
- 두번쨴 gating unit을 이용하여 해결하는 것이다. ex) LSTM, GRU ...
3. Gated Recurrent Neural Networks
3.1. Long Short-Term Memory Unit
- LSTM에 대한 내용은 해당 포스팅을 참고하기 바란다.
https://ceulkun04.tistory.com/138
[논문 리뷰] [Deep Learning] Long Short-Term Memory
0. Referencehttps://ieeexplore.ieee.org/abstract/document/6795963 Long Short-Term MemoryLearning to store information over extended time intervals by recurrent backpropagation takes a very long time, mostly because of insufficient, decaying error backflow
ceulkun04.tistory.com
https://ceulkun04.tistory.com/139
[논문 리뷰] [Deep Learning] LSTM: A Search Space Odyssey
0. Referencehttps://arxiv.org/abs/1503.04069 LSTM: A Search Space OdysseySeveral variants of the Long Short-Term Memory (LSTM) architecture for recurrent neural networks have been proposed since its inception in 1995. In recent years, these networks have
ceulkun04.tistory.com
3.2. Gate Recurrent Unit
- GRU는 각 Recurrent Unit이 다양한 Time scale의 의존성을 적응할 수 있게 학습할 수 있도록 설계되었다.
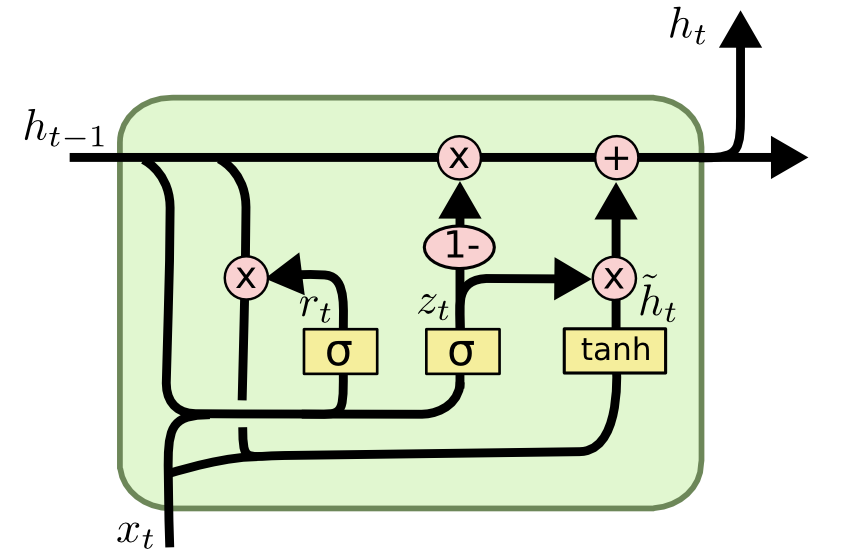
- LSTM과 유사하게, GRU는 정보의 흐름을 조절하는 gate를 포함하고 있지만, 별도의 memory cell을 포함하진 않는다.
- GRU의 activation h(j,t)는 이전의 h(j,t-1)과 candidate activation h(j,t)사이의 linear interpolation으로 정의된다.
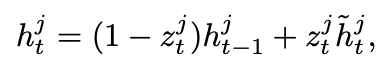
- 여기서 z_t는 update gate로서, 유닛이 얼마나 활성화를 갱신할지 결정하는 역할을한다.
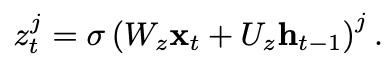
- 이처럼 기존 상태와 새롭게 계산된 상태의 Lienar combination을 수행하는 과정은 LSTM과 유사하다.
- 그러나, GRU는 자신의 상태를 얼마나 노출할지 제어하는 메커니즘이 없으며, 매 time step마다 전체 상태를 노출하게 된다.
- candidate activation h는 다음과 같이 계산된다.
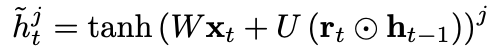
- 여기서 r_t는 reset gate이며, reset gate가 off(r_t == 0)일때,
- 해당 유닛은 마치 입력 sequence의 첫번째 기호를 읽는 것처럼 동작하여 이전 상태를 효과적으로 잊을 수 있도록 한다.
- reset gate는 update gate와 유사한 방식으로 계산된다.
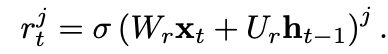
3.3. Discussion
- LSTM과 GRU 사이에는 몇 가지 공통점이 존재한다.
- 가장 큰 공통점은 시점 t에서 t+1로의 update가 additive componet로 이루어진다는 것이다.
- 이는 기존의 tranditional recurrent unit에는 없는 특징이다.
- 즉, 기존 상태를 유지하면서 새로운 정보를 추가하는 방식으로 업데이트된다는 의미이다.
- 이러한 additive nature는 두 가지 이점을 제공한다.
i) 장기간 정보 유지 가능
- LSTM의 forget gate나 GRU의 Update gate에 의해 중요한 특징으로 판단된 정보는 덮어쓰이지 않고 유지된다.
ii) Gradient Vanish 완화
- 여러 시점(각 gate)을 뛰어넘는 shortcut path를 효과적으로 형성하게 된다.
- 이를 통해 Backpropagation 과정에서 gradient가 너무 빠르게 사라지는것을 방지하게 된다.
- 반면에 LSTM과 GRU의 차이점도 존재한다.
i) 메모리 내용의 노출 제어 여부
- LSTM : output gate를 통해 메모리 내용이 얼마나 외부로 노출될 지 조절할 수 있다.
- GRU : 별도의 제어 없이 모든 메모리 상태를 그대로 노출한다.
ii) Input gate와 reset gate의 역할 차이
- LSTM : 새로운 메모리 내용을 계산할 때, 이전 시점의 정보가 얼마나 반영될지 별도로 조절하지 않는다.
대신, forget gate와는 독립적으로 새로운 메모리 내용이 얼마나 추가될지 조절한다,
- GRU : 새로운 candidate activation을 계산할 때, 이전 시점의 정보가 얼마나 반영될지 reset gate를 이용해 조절한다.
하지만, candidate activation을 얼마나 더해질지 따로 제어하지 않고, update gate와 연동되어 결정된다.
4. Conclusion
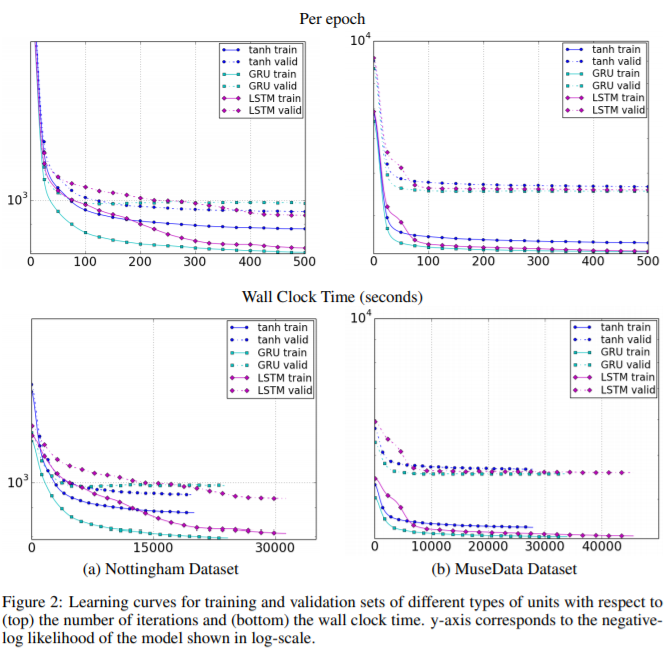
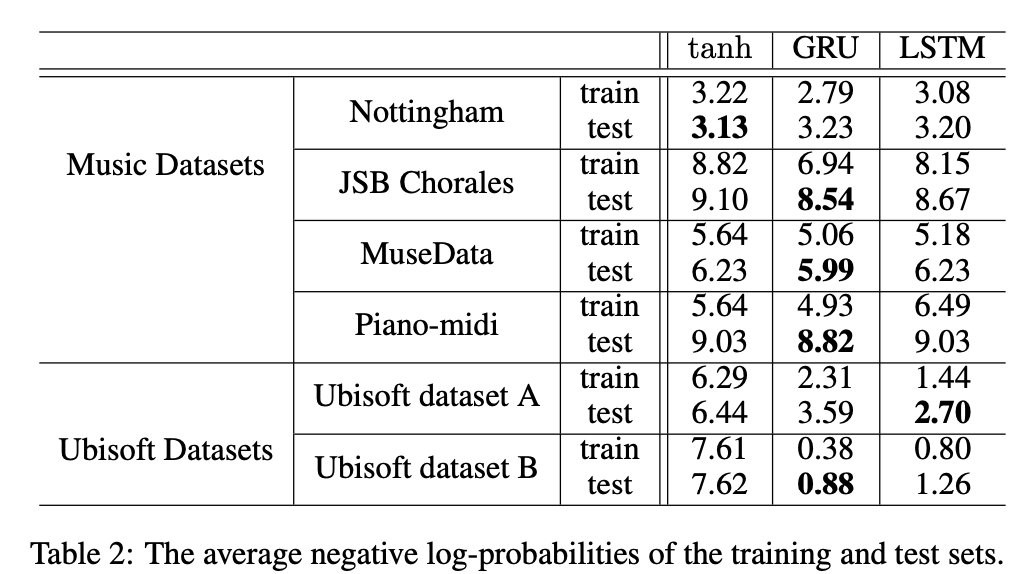
- polynomic music dataset의 경우 GRU가 LSTM,tanh-RNN보다 더 나은 결과를 보이는 것을 알 수 있고,
- 그러나 특정문제에선 LSTM이 더 나은 결과를 보이는 경우도 존재하였다.
- LSTM,GRU는 tanh-RNN보다 우수하다고 말할 수 있지만,
- GRU와 LSTM중 어느 것이 더 우수한지에 대한 명확한 결론을 내리긴 어렵다고 한다.
'Paper Review(논문 리뷰) > Deep Learning' 카테고리의 다른 글
| [논문 리뷰] [Deep Learning] Memory Networks (0) | 2025.02.07 |
|---|---|
| [눈문 리뷰] [Deep Learning] Sequence to Sequence Learning with Neural Networks (0) | 2025.02.05 |
| [논문 리뷰] [Deep Learning] LSTM: A Search Space Odyssey (1) | 2025.02.05 |
| [논문 리뷰] [Deep Learning] Long Short-Term Memory (1) | 2025.02.04 |
| [논문 리뷰] [Deep Learning] Machine Learning Students Overfit to Overfitting (1) | 2025.02.01 |
0. Reference
https://arxiv.org/abs/1412.3555
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
In this paper we compare different types of recurrent units in recurrent neural networks (RNNs). Especially, we focus on more sophisticated units that implement a gating mechanism, such as a long short-term memory (LSTM) unit and a recently proposed gated
arxiv.org
1. Introduction
- RNN은 최근 여러 머신러닝 작업에서 유의미한 성과를 보이고 있다.
- 특히, 입출력의 길이가 가변적인 경우 효과적이다.
- 본 논문에선 LSTM, GRU, tanh model 세개의 모델에 대해서 평가하였다고 한다.
2. Background : Recurrent Neural Network
- RNN은 기존의 feedforward neural network를 확장한 형태로, 가변 길이의 시퀀스를 처리할 수 있는 신경망이다.
- RNN은 매 시점의 활성화 상태가 이전 시점의 활성화 상태에 의존하는 순환 상태를 가짐으로써 가변 길이의 시퀀스를 처리할 수있다.
- 수식으로 나타내면 다음과 같이 업데이트를 한다는 걸 알 수 있다.
- 여기서 phi는 nonlinear function이다.
- 조금더 일반화하자면 다음과 같다.
- generative RNN은 주어진 state h_t에 대하여 sequence의 다음 element에 대한 확률분포를 생성한다.
- 그 Sequence Proability는 다음과 같이 decompose된다
- 여기서 마지막 element는 sequence의 끝을 나타내는 특수한 값이다. 각 조건부 확률 분포를 다음과 같이 모델링 시킬 수 있다.
- 이러한 generative RNN이 본 논문의 주제라고 한다.
- 여기서, 길이가 긴 Input이 들어오게 되면 RNN은 long-term dependencies를 포착하도록 학습하기 어렵기 때문에,
- gradient vanish나 gradient explode가 발생하게 된다.
- 이러한 문제를 해결하기위해서 두 가지 방식으로 시도했다고 하는데,
- 첫번짼 SGD가 아닌 다른 Optimization을 사용하는 것이고,
- 두번쨴 gating unit을 이용하여 해결하는 것이다. ex) LSTM, GRU ...
3. Gated Recurrent Neural Networks
3.1. Long Short-Term Memory Unit
- LSTM에 대한 내용은 해당 포스팅을 참고하기 바란다.
https://ceulkun04.tistory.com/138
[논문 리뷰] [Deep Learning] Long Short-Term Memory
0. Referencehttps://ieeexplore.ieee.org/abstract/document/6795963 Long Short-Term MemoryLearning to store information over extended time intervals by recurrent backpropagation takes a very long time, mostly because of insufficient, decaying error backflow
ceulkun04.tistory.com
https://ceulkun04.tistory.com/139
[논문 리뷰] [Deep Learning] LSTM: A Search Space Odyssey
0. Referencehttps://arxiv.org/abs/1503.04069 LSTM: A Search Space OdysseySeveral variants of the Long Short-Term Memory (LSTM) architecture for recurrent neural networks have been proposed since its inception in 1995. In recent years, these networks have
ceulkun04.tistory.com
3.2. Gate Recurrent Unit
- GRU는 각 Recurrent Unit이 다양한 Time scale의 의존성을 적응할 수 있게 학습할 수 있도록 설계되었다.
- LSTM과 유사하게, GRU는 정보의 흐름을 조절하는 gate를 포함하고 있지만, 별도의 memory cell을 포함하진 않는다.
- GRU의 activation h(j,t)는 이전의 h(j,t-1)과 candidate activation h(j,t)사이의 linear interpolation으로 정의된다.
- 여기서 z_t는 update gate로서, 유닛이 얼마나 활성화를 갱신할지 결정하는 역할을한다.
- 이처럼 기존 상태와 새롭게 계산된 상태의 Lienar combination을 수행하는 과정은 LSTM과 유사하다.
- 그러나, GRU는 자신의 상태를 얼마나 노출할지 제어하는 메커니즘이 없으며, 매 time step마다 전체 상태를 노출하게 된다.
- candidate activation h는 다음과 같이 계산된다.
- 여기서 r_t는 reset gate이며, reset gate가 off(r_t == 0)일때,
- 해당 유닛은 마치 입력 sequence의 첫번째 기호를 읽는 것처럼 동작하여 이전 상태를 효과적으로 잊을 수 있도록 한다.
- reset gate는 update gate와 유사한 방식으로 계산된다.
3.3. Discussion
- LSTM과 GRU 사이에는 몇 가지 공통점이 존재한다.
- 가장 큰 공통점은 시점 t에서 t+1로의 update가 additive componet로 이루어진다는 것이다.
- 이는 기존의 tranditional recurrent unit에는 없는 특징이다.
- 즉, 기존 상태를 유지하면서 새로운 정보를 추가하는 방식으로 업데이트된다는 의미이다.
- 이러한 additive nature는 두 가지 이점을 제공한다.
i) 장기간 정보 유지 가능
- LSTM의 forget gate나 GRU의 Update gate에 의해 중요한 특징으로 판단된 정보는 덮어쓰이지 않고 유지된다.
ii) Gradient Vanish 완화
- 여러 시점(각 gate)을 뛰어넘는 shortcut path를 효과적으로 형성하게 된다.
- 이를 통해 Backpropagation 과정에서 gradient가 너무 빠르게 사라지는것을 방지하게 된다.
- 반면에 LSTM과 GRU의 차이점도 존재한다.
i) 메모리 내용의 노출 제어 여부
- LSTM : output gate를 통해 메모리 내용이 얼마나 외부로 노출될 지 조절할 수 있다.
- GRU : 별도의 제어 없이 모든 메모리 상태를 그대로 노출한다.
ii) Input gate와 reset gate의 역할 차이
- LSTM : 새로운 메모리 내용을 계산할 때, 이전 시점의 정보가 얼마나 반영될지 별도로 조절하지 않는다.
대신, forget gate와는 독립적으로 새로운 메모리 내용이 얼마나 추가될지 조절한다,
- GRU : 새로운 candidate activation을 계산할 때, 이전 시점의 정보가 얼마나 반영될지 reset gate를 이용해 조절한다.
하지만, candidate activation을 얼마나 더해질지 따로 제어하지 않고, update gate와 연동되어 결정된다.
4. Conclusion
- polynomic music dataset의 경우 GRU가 LSTM,tanh-RNN보다 더 나은 결과를 보이는 것을 알 수 있고,
- 그러나 특정문제에선 LSTM이 더 나은 결과를 보이는 경우도 존재하였다.
- LSTM,GRU는 tanh-RNN보다 우수하다고 말할 수 있지만,
- GRU와 LSTM중 어느 것이 더 우수한지에 대한 명확한 결론을 내리긴 어렵다고 한다.
'Paper Review(논문 리뷰) > Deep Learning' 카테고리의 다른 글
| [논문 리뷰] [Deep Learning] Memory Networks (0) | 2025.02.07 |
|---|---|
| [눈문 리뷰] [Deep Learning] Sequence to Sequence Learning with Neural Networks (0) | 2025.02.05 |
| [논문 리뷰] [Deep Learning] LSTM: A Search Space Odyssey (1) | 2025.02.05 |
| [논문 리뷰] [Deep Learning] Long Short-Term Memory (1) | 2025.02.04 |
| [논문 리뷰] [Deep Learning] Machine Learning Students Overfit to Overfitting (1) | 2025.02.01 |