
1.Introduce MNIST

- MNIST 데이터 셋은 0부터 9까지의 손글씨 이미지로 구성
- 훈련 데이터 60,000장 / 테스트 데이터 10,000장
- 각 데이터는 이미지와 라벨로 이루어짐
- 각 이미지는 28 * 28 해상도의 흑백사진
- 각 픽셀은 0~255로 밝기표현이 되어있음 (0: 검정 / 255: 흰색)
2. MNIST 데이터 출력
- MNIST라는 데이터베이스에 대해서 알아봤다면, 한번 실제로 출력해보자.
https://github.com/WegraLee/deep-learning-from-scratch
GitHub - WegraLee/deep-learning-from-scratch: 『밑바닥부터 시작하는 딥러닝』(한빛미디어, 2017)
『밑바닥부터 시작하는 딥러닝』(한빛미디어, 2017). Contribute to WegraLee/deep-learning-from-scratch development by creating an account on GitHub.
github.com
- 해당 깃헙에서 데이터를 다운로드 할 수 있다.
2.1. MNIST 불러오기
import pickle
from dataset.mnist import load_mnist
(x_train, t_train), (x_test, t_test) = \
load_mnist(flatten=True, normalize=False)
-------------------------------------------------------
Converting train-images-idx3-ubyte.gz to NumPy Array ...
Done
Converting train-labels-idx1-ubyte.gz to NumPy Array ...
Done
Converting t10k-images-idx3-ubyte.gz to NumPy Array ...
Done
Converting t10k-labels-idx1-ubyte.gz to NumPy Array ...
Done
Creating pickle file ...
Done!- load_mnist() 라는 함수를 이용하여 MNIST DATA를 불러올 수 있다.
- flatten : Flatten할지 안할지의 여부 체크 (flatten은 뒤에 설명한다.)
- normalize : 0~255 였던 데이터를 0~1사이로 범위를 정해줄지 여부 체크
2.2. PIL을 이용하여 MNIST출력
from PIL import Image
import numpy as np
def img_show(img):
pil_img = Image.fromarray(np.uint8(img))
pil_img.show()
img = x_train[0]
img = img.reshape(28,-1)
- PIL을 이용하여 출력하는 방식은 현재 많이 사용되는 방식은 아니라서 이런 방식이 있다는 것만 알고 넘어가자
2.3. MNIST Data를 행렬로
np.set_printoptions(linewidth=200,threshold=1000)
x_train[0]cf) np.set_printoptions(??) : 출력하는 사이즈를 설정가능하게 해줌
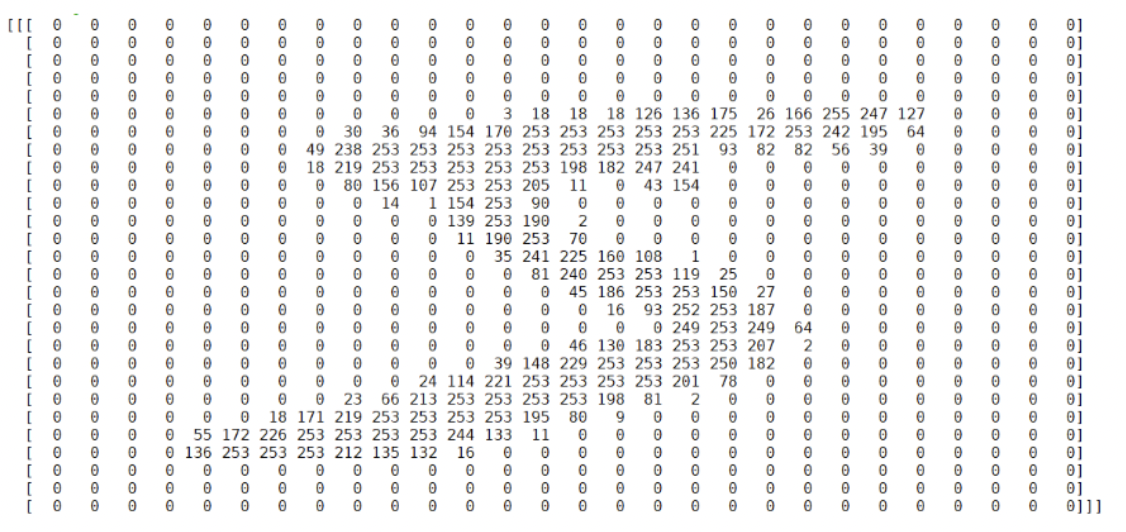
- 만일 Flatten을 시키면 어떻게 될까?
2.4.Flatten
- 다음과 같이 행렬이 주어져있다고 생각해보자.
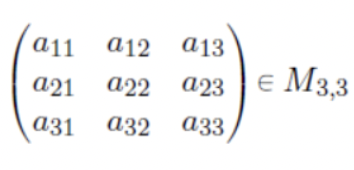
- 이 행렬을 한줄로 이어 붙여 벡터로 만들어주는 작업을 해보자.
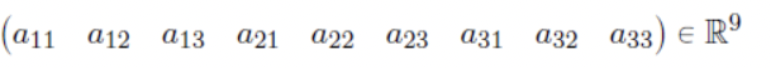
- 이런 작업을 Flatten이라고 한다.
- 마치 세절기로 종이를 찢어서 한줄로 이어놓는것과 같다.

- 즉, MNIST 데이터 하나를 Flatten해서 신경망의 입력벡터로 사용한다고 생각하면 편하다.
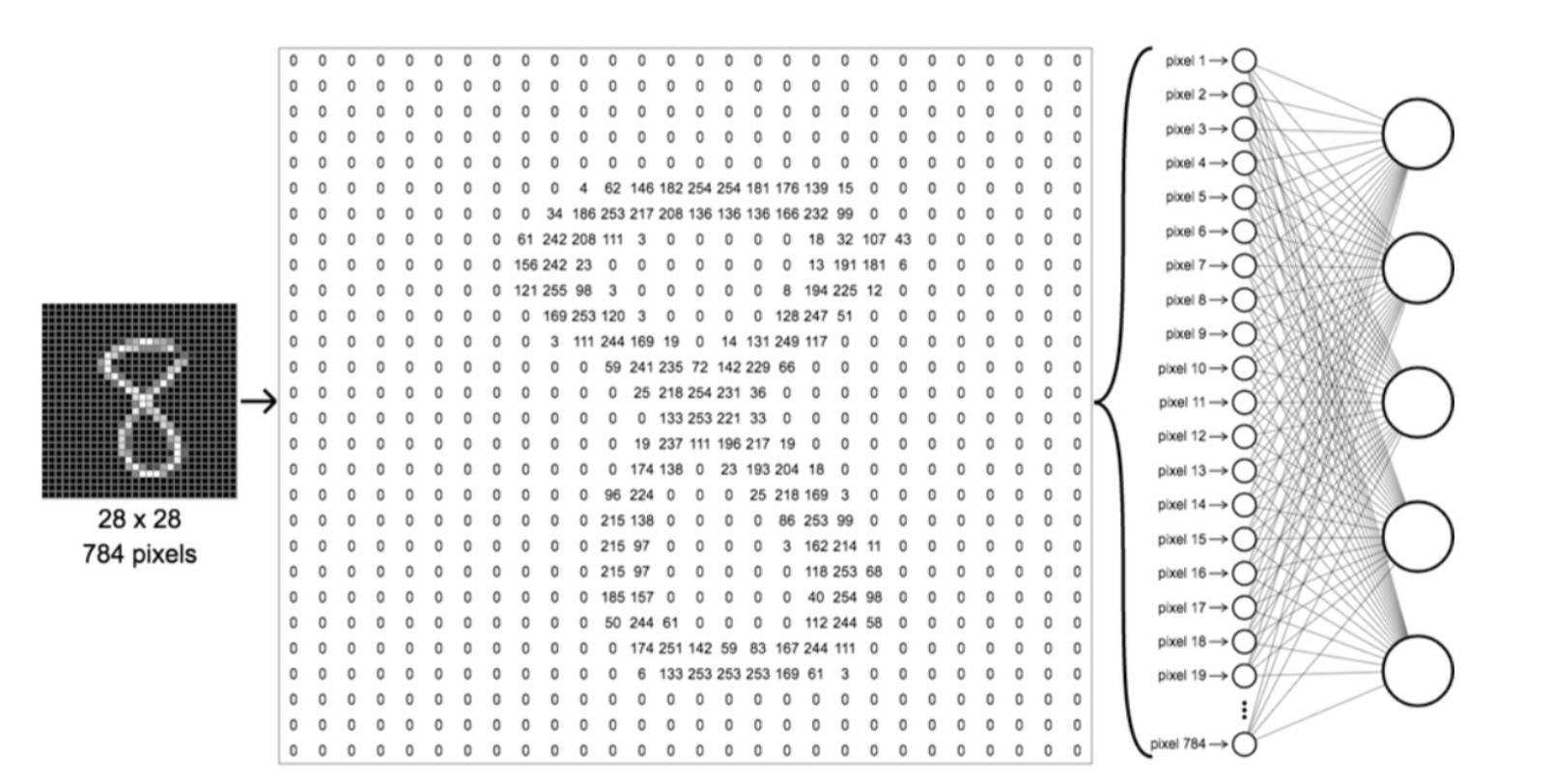
3. MNIST 신경망 구현
- 밑시딥1에 있는 sample_weight를 이용해서 가볍게 MNIST 데이터를 구분하는 신경망을 구현해보자.
- 함수 정의
import pickle
from dataset.mnist import load_mnist
from common.functions import *
import numpy as np
def get_data():
(x_train, t_train), (x_test, t_test) = \
load_mnist(flatten=True, normalize=True,one_hot_label=False)
return x_test,t_test
def init_network():
with open("ch03/sample_weight.pkl","rb") as f:
network = pickle.load(f)
return network
def predict(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x,W1) +b1
z1 = sigmoid(a1)
a2 = np.dot(z1,W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2,W3) + b3
y = softmax(a3)
return y

- 예제
x,t = get_data()
network = init_network()
accuracy_cnt = 0
for i in range(len(x)):
y = predict(network,x[i])
p = np.argmax(y) #확률이 가장 높은 인덱스
if p == t[i]:
accuracy_cnt +=1
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))
----------------------------------------------------------------
Output
Accuracy:0.9352
4. Mini Batch
- 밑시딥1 에선 배치(Batch)라고 명칭되어 있지만 미니배치라고 알고 있는게 편하다.
- 미니배치(Mini Batch)란 쉽게 설명하면 묶음 이라고 생각하면된다.
- 지금까지 신경망을 돌릴 때, input data를 한개씩 집어넣었는데, 이를 10장, 50장 이렇게 묶어서 넣는걸 의미한다.
- 이렇게 될경우 I/O 병목현상을 줄여줄수 있음.

- 코드는 다음과 같다.
batch_size = 100
accuracy_cnt = 0
for i in range(0,len(x),batch_size):
x_batch = x[i:i+batch_size]
y_batch = predict(network,x_batch)
p = np.argmax(y_batch, axis = 1)
accuracy_cnt += np.sum(p==t[i:i+batch_size])
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))
----------------------------------------------------
Accuracy:0.9352'DS Study > 밑바닥부터 시작하는 딥러닝 1' 카테고리의 다른 글
| [밑시딥1] [5] 손실함수(Loss Function) (0) | 2024.07.29 |
|---|---|
| [밑시딥1] [3] 인공신경망(ANN) (1) | 2024.07.26 |
| [밑시딥1] [2] 활성화함수 (Activation Function) (0) | 2024.07.26 |
| [밑시딥1] [1] 퍼셉트론 (Perceptron) (0) | 2024.07.24 |