
0. Reference
https://arxiv.org/abs/1409.4842
Going Deeper with Convolutions
We propose a deep convolutional neural network architecture codenamed "Inception", which was responsible for setting the new state of the art for classification and detection in the ImageNet Large-Scale Visual Recognition Challenge 2014 (ILSVRC 2014). The
arxiv.org
1. Introduction
- 본 논문에선 Image Classification에서 Deep Learning이 발전한 이유는,
- 하드웨어의 발전, 대규모 데이터셋, 더 큰 모델가 이유라곤 하지만 더 큰 이유는,
- 새로운 아이디어, 개선된 알고리즘, 발전된 Network Architecture가 핵심이라고 한다.
- 본 논문에서의 주된 아이디어는 "Inception"이라는 Network Architecture이다.
- Inception이라는 이름은 NIN("Network In Network")라는 논문과
- 인터넷 밈중 하나인 "We need to go deeper"에서 영감을 얻었다고 한다.
- 기존의 CNN과는 다르게 Inception을 도입하여, Network의 Depth를 논리적으로 증가시켰다.
2. Related Work
- GoogLeNet은 기본적으로 LeNet5의 구조를 유사하게 들고가면서, Inception 구조를 이용하여 depth를 증가시켰다고 볼 수있다.
- 뿐만 아니라, Network In Network에서 1 x 1 ConVLayer를 활용하여, Depth뿐 아니라, width도 넓힐 수 있었다고 한다.
3. Motivation and High Level Considerations
- DNN의 성능을 높이는 가장 단순하면서 정확한 방법은 크기를 키우는 것이라고 한다.
- 이는 network의 Depth와 width(유닛의 개수)를 키우는 것을 의미하는데,
- 두 가지 단점이 존재한다.
i) parameter가 증가하기에 Overfitting에 취약함
ii) 해상도가 크면 클수록 더 큰 계산비용을 야기하게 된다.
- 해당 문제를 해결하기 위해선, Fully Connected된 부분을 Sparse하게 연결하는 것이고,
- 이를 ConVL에서도 적용하면 된다고 주장한다.

- 이렇게 Sparse하게 연결하면 생기는 장점은 "같이 잘맞는 뉴런은 서로 연결되어있다."라는 Hebbian priciple과 유사하기 때문이다.
- 즉, 어떤 task에 대해 장점을 보이는 뉴런의 weight는 증가시키고, 아닌 애들은 감소시키는 역할을 할 수 있다는 것이다.
- 하지만, Sparse한 구조를 다룰 땐 계산비용이 Dense할때보다 더 많이 소요된다고 한다.
- 그럼에도 불구하고, Sparse matrix를 operation한 문헌들이 많이 나오게 되었는데,
- Sparse matrix를 clustering하여 Dense한 Submatrix를 만드는 연구에서 좋은 성능을 보였다고 한다.
- 그래서 해당 구조를 시험하기 위해, Inception이라는 구조가 나오게 되었다.
4. Architecture Details
- Inception의 주요 아이디어는 CNN에서 Optimal한 local Sparse structure를
- 어떻게 즉시 사용 가능한 dense component로 근사하고 구성할 수 있는지를 찾는 것이다.
- 우선 dense component로 근사시키기 위해서, local sparse structure를 반복적으로 추출하고,
- 이러한 feature last-layer에서 correlation을 분석하여 상관도가 높은 unit을 cluster로 그룹화하여,
- dense하게 근사시킬수 있게 된다.
- local sparse structure를 반복적으로 추출한다는 것에 대한 의미를 좀 더 자세히 알아보자.
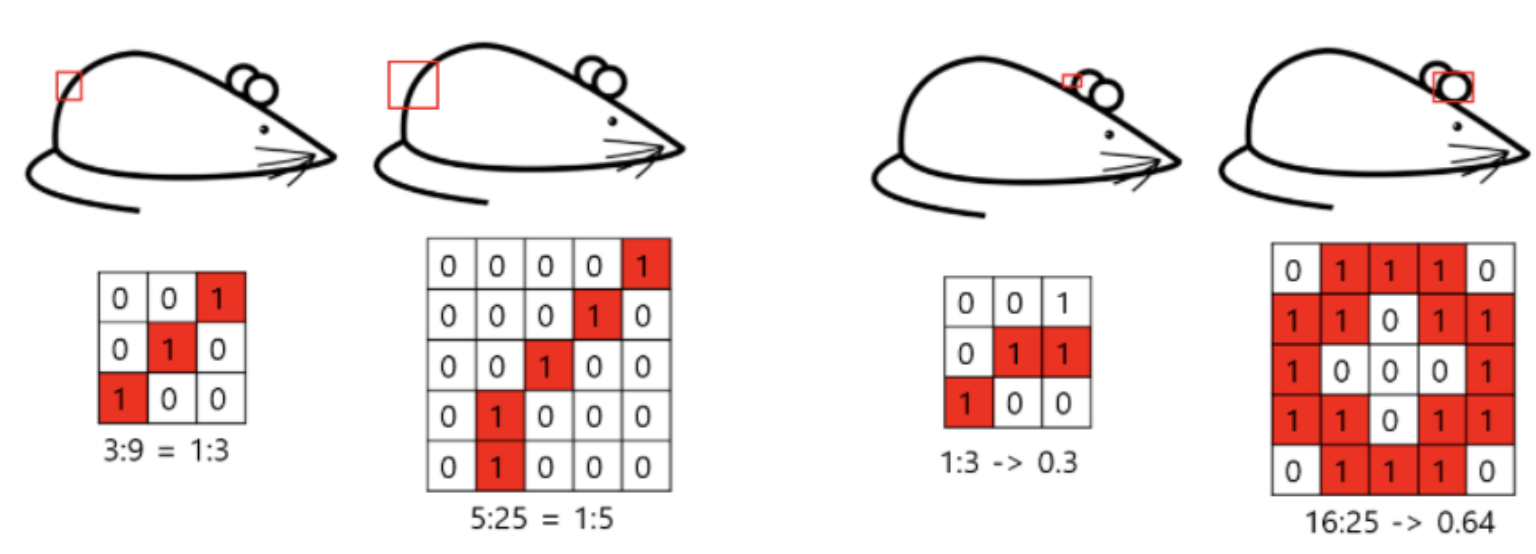
- 왼쪽 쥐 같은 경우, 3x3이나 5x5이나 추출되는 feature는 유사하지만,
- 오른쪽 쥐 같은 경우, 3x3과 5x5가 추출하는 feature가 달라지게 된다.
--> 5x5가 더 feature를 잘 추출하게 된다.
- 그 이유는, 귀라는 feature의 크기가 단순히 크기때문에 3x3으론 feature를 추출을 못하기 때문이다.
- 이렇듯 다양한 필터 사이즈를 가지고 여러가지 feature map을 뽑아내(Sparse structure)
cf)
:: 1x1 conv:: 작은 feature
:: 3x3 conv:: 중간 feature
:: 5x5 conv:: 큰 feature
:: max pooling:: 중요한정보요약
- 다음과 같이 Dense하게 이어줘 correlation을 찾아주는 식이다.
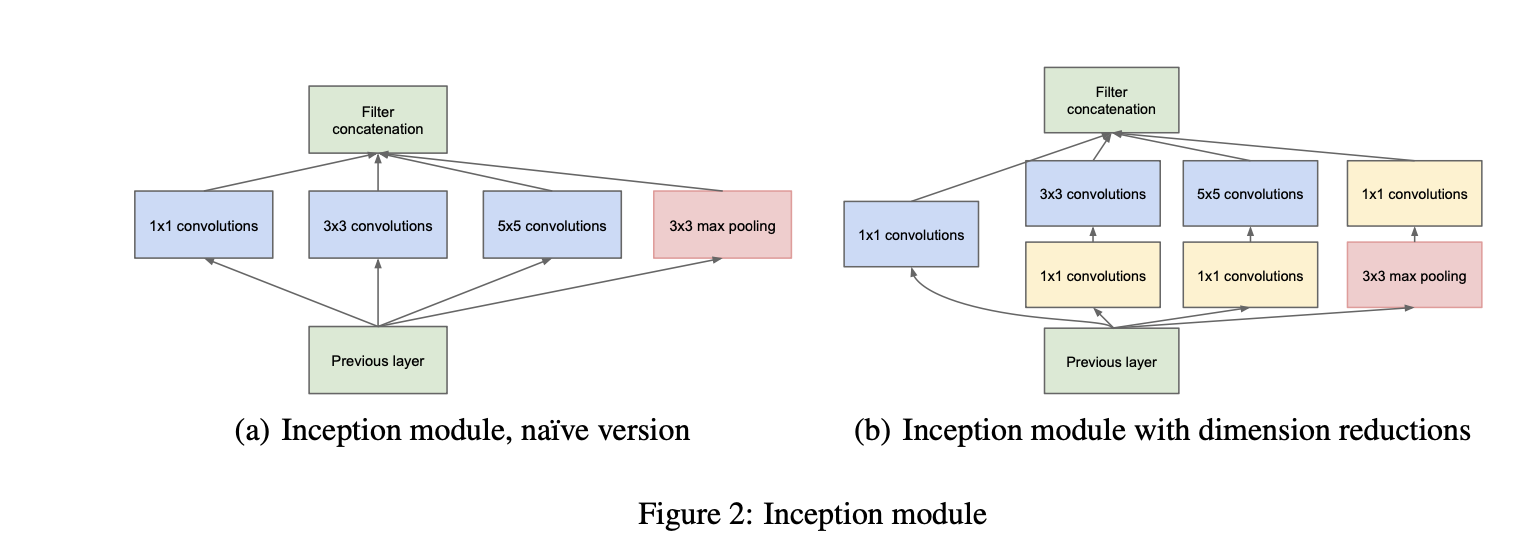
(b)에서 1x1 convolutions을 사용하여 Channel개수를 줄여 계산비용을 줄여줄 수 있다.
- 그로 인해, Channel 수를 줄였기 때문에, ConV에서의 filter 수 역시 줄어들게 되기 때문에 계산을 확 줄일수 있다.
- ReLU도 적용이 되기에, non-linearity도 더해주는 역할을 하게 된다.
- 이러한 inception구조는 낮은 층에서는 복잡한 구조를 필요로 하지 않으니, tranditional ConV로 진행되고,
- 깊어짐에 따라 inception을 적용하는 구조라고 생각하면 좋다.
- Filter Concatenation되는 부분들은 각각의 필터들을 통과해서 나오게된 feature map을 동일하게 만들어 concat하게 된다.
- 동일하게 만드는 과정은, 각기 다른 stride나 padding을 적용하여 이루어 진다.
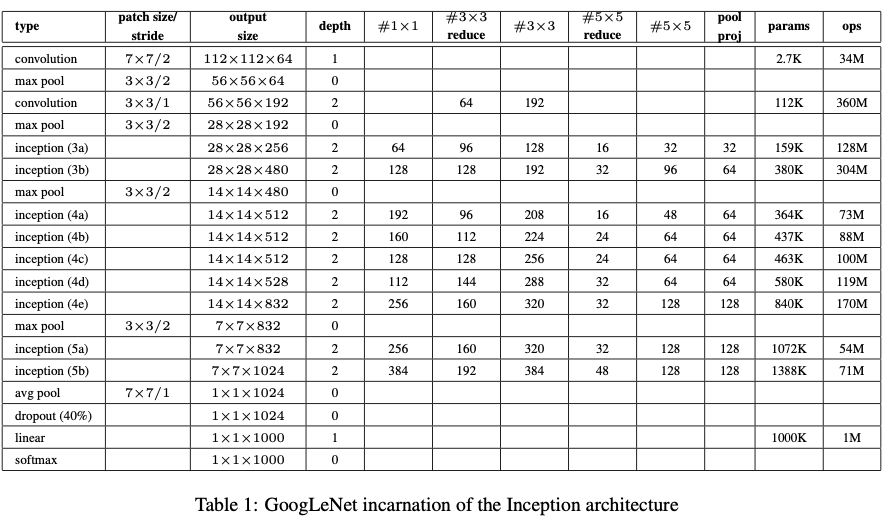
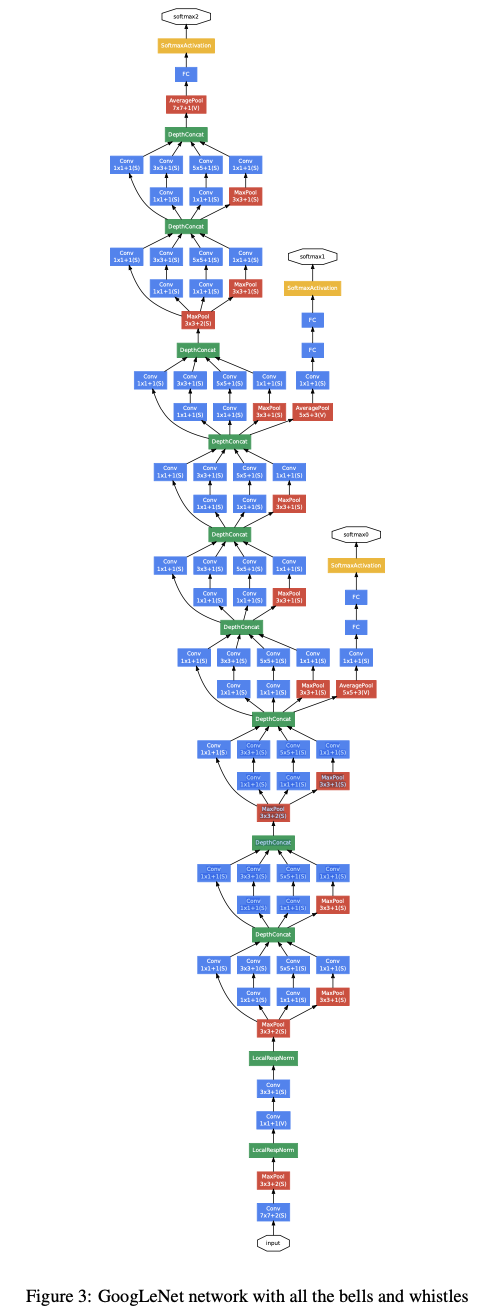
5. GoogLeNet
- 마지막 FC-layer와 연결하기 위해서 GAP(Gloval average pooling)을 사용하였다.
'Paper Review(논문 리뷰) > Computer Vision' 카테고리의 다른 글
| [논문 리뷰] [CV] Deep Residual Learning for Image Recognition (0) | 2025.03.21 |
|---|---|
| [논문 리뷰] [CV] Rethinking the Inception Architecture for Computer Vision (0) | 2025.03.19 |
| [논문 리뷰] [CV] VERY DEEP CONVOLUTIONAL NETWORKSFOR LARGE-SCALE IMAGE RECOGNITION (0) | 2025.03.17 |
| [논문 리뷰] [CV] Network In Network (0) | 2025.03.17 |
| [논문 리뷰] [CV] Visualizing and Understanding Convolutional Networks (1) | 2025.03.17 |
0. Reference
https://arxiv.org/abs/1409.4842
Going Deeper with Convolutions
We propose a deep convolutional neural network architecture codenamed "Inception", which was responsible for setting the new state of the art for classification and detection in the ImageNet Large-Scale Visual Recognition Challenge 2014 (ILSVRC 2014). The
arxiv.org
1. Introduction
- 본 논문에선 Image Classification에서 Deep Learning이 발전한 이유는,
- 하드웨어의 발전, 대규모 데이터셋, 더 큰 모델가 이유라곤 하지만 더 큰 이유는,
- 새로운 아이디어, 개선된 알고리즘, 발전된 Network Architecture가 핵심이라고 한다.
- 본 논문에서의 주된 아이디어는 "Inception"이라는 Network Architecture이다.
- Inception이라는 이름은 NIN("Network In Network")라는 논문과
- 인터넷 밈중 하나인 "We need to go deeper"에서 영감을 얻었다고 한다.
- 기존의 CNN과는 다르게 Inception을 도입하여, Network의 Depth를 논리적으로 증가시켰다.
2. Related Work
- GoogLeNet은 기본적으로 LeNet5의 구조를 유사하게 들고가면서, Inception 구조를 이용하여 depth를 증가시켰다고 볼 수있다.
- 뿐만 아니라, Network In Network에서 1 x 1 ConVLayer를 활용하여, Depth뿐 아니라, width도 넓힐 수 있었다고 한다.
3. Motivation and High Level Considerations
- DNN의 성능을 높이는 가장 단순하면서 정확한 방법은 크기를 키우는 것이라고 한다.
- 이는 network의 Depth와 width(유닛의 개수)를 키우는 것을 의미하는데,
- 두 가지 단점이 존재한다.
i) parameter가 증가하기에 Overfitting에 취약함
ii) 해상도가 크면 클수록 더 큰 계산비용을 야기하게 된다.
- 해당 문제를 해결하기 위해선, Fully Connected된 부분을 Sparse하게 연결하는 것이고,
- 이를 ConVL에서도 적용하면 된다고 주장한다.
- 이렇게 Sparse하게 연결하면 생기는 장점은 "같이 잘맞는 뉴런은 서로 연결되어있다."라는 Hebbian priciple과 유사하기 때문이다.
- 즉, 어떤 task에 대해 장점을 보이는 뉴런의 weight는 증가시키고, 아닌 애들은 감소시키는 역할을 할 수 있다는 것이다.
- 하지만, Sparse한 구조를 다룰 땐 계산비용이 Dense할때보다 더 많이 소요된다고 한다.
- 그럼에도 불구하고, Sparse matrix를 operation한 문헌들이 많이 나오게 되었는데,
- Sparse matrix를 clustering하여 Dense한 Submatrix를 만드는 연구에서 좋은 성능을 보였다고 한다.
- 그래서 해당 구조를 시험하기 위해, Inception이라는 구조가 나오게 되었다.
4. Architecture Details
- Inception의 주요 아이디어는 CNN에서 Optimal한 local Sparse structure를
- 어떻게 즉시 사용 가능한 dense component로 근사하고 구성할 수 있는지를 찾는 것이다.
- 우선 dense component로 근사시키기 위해서, local sparse structure를 반복적으로 추출하고,
- 이러한 feature last-layer에서 correlation을 분석하여 상관도가 높은 unit을 cluster로 그룹화하여,
- dense하게 근사시킬수 있게 된다.
- local sparse structure를 반복적으로 추출한다는 것에 대한 의미를 좀 더 자세히 알아보자.
- 왼쪽 쥐 같은 경우, 3x3이나 5x5이나 추출되는 feature는 유사하지만,
- 오른쪽 쥐 같은 경우, 3x3과 5x5가 추출하는 feature가 달라지게 된다.
--> 5x5가 더 feature를 잘 추출하게 된다.
- 그 이유는, 귀라는 feature의 크기가 단순히 크기때문에 3x3으론 feature를 추출을 못하기 때문이다.
- 이렇듯 다양한 필터 사이즈를 가지고 여러가지 feature map을 뽑아내(Sparse structure)
cf)
:: 1x1 conv:: 작은 feature
:: 3x3 conv:: 중간 feature
:: 5x5 conv:: 큰 feature
:: max pooling:: 중요한정보요약
- 다음과 같이 Dense하게 이어줘 correlation을 찾아주는 식이다.
(b)에서 1x1 convolutions을 사용하여 Channel개수를 줄여 계산비용을 줄여줄 수 있다.
- 그로 인해, Channel 수를 줄였기 때문에, ConV에서의 filter 수 역시 줄어들게 되기 때문에 계산을 확 줄일수 있다.
- ReLU도 적용이 되기에, non-linearity도 더해주는 역할을 하게 된다.
- 이러한 inception구조는 낮은 층에서는 복잡한 구조를 필요로 하지 않으니, tranditional ConV로 진행되고,
- 깊어짐에 따라 inception을 적용하는 구조라고 생각하면 좋다.
- Filter Concatenation되는 부분들은 각각의 필터들을 통과해서 나오게된 feature map을 동일하게 만들어 concat하게 된다.
- 동일하게 만드는 과정은, 각기 다른 stride나 padding을 적용하여 이루어 진다.
5. GoogLeNet
- 마지막 FC-layer와 연결하기 위해서 GAP(Gloval average pooling)을 사용하였다.
'Paper Review(논문 리뷰) > Computer Vision' 카테고리의 다른 글
| [논문 리뷰] [CV] Deep Residual Learning for Image Recognition (0) | 2025.03.21 |
|---|---|
| [논문 리뷰] [CV] Rethinking the Inception Architecture for Computer Vision (0) | 2025.03.19 |
| [논문 리뷰] [CV] VERY DEEP CONVOLUTIONAL NETWORKSFOR LARGE-SCALE IMAGE RECOGNITION (0) | 2025.03.17 |
| [논문 리뷰] [CV] Network In Network (0) | 2025.03.17 |
| [논문 리뷰] [CV] Visualizing and Understanding Convolutional Networks (1) | 2025.03.17 |