
0. Reference
https://arxiv.org/abs/1512.00567
Rethinking the Inception Architecture for Computer Vision
Convolutional networks are at the core of most state-of-the-art computer vision solutions for a wide variety of tasks. Since 2014 very deep convolutional networks started to become mainstream, yielding substantial gains in various benchmarks. Although incr
arxiv.org
1. Introduction
- Inception의 복잡성은 네트워크를 수정하는 것을 어렵게 만든다.
- 단순히 구조를 무작정 확정하면, 많은 연산상의 이점이 즉시 사라질 수 있다.
- 또한 Inception v1논문에서의 GoogLeNet의 구조에 대한 명확한 설명이 논문에서 제공되지 않기 때문에,
- 이를 새로운 사용 사례에 맞게 조정하는 것이 어렵다고 한다.
- 그래서, 본 논문에서는 CNN을 효율적으로 확장하기 위한 몇 가지 아이디어를 설명하고,
- 모델의 높은 품질을 유지하기 위해 반드시 지켜야 할 몇 가지 원칙들을 소개하고 있다.
2. General Design Principle
- CNN을 설계할 때, 지키면 좋은 원칙들을 소개하고 있다.
- 확실하게 증명은 되질않아, 추가적인 실험이 필요하다고 한다.
2.1. Representational Bottleneck 피하기(Network 초반)
- Feed-forward network에서는 input layer부터 classifier 혹은 regressor까지 acyclic graph로 표현될 수 있으며,
- 이는 정보 흐름의 방향이 명확함을 의미한다.
- 즉, 신경망을 임의로 잘라냈을때 우리는 그 절단면의 정보량을 측정할 수 있다.
- 이 때, 지나치게 낮은 차원으로 매핑하려할 때, Bottlenect현상이 발생한다.
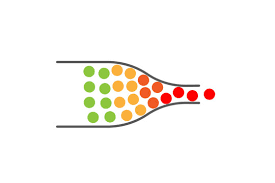
- 이때, Bottleneck현상이 발생하게 되면,feature가 뭉게져 효율적인 학습이 어렵다.
- 그렇기 때문에, Bottlenect현상을 피해도록 모델링해야한다.
- 일반적으로, Input부터 Output까지 부드럽게 차원을 감소시키는것이 바람직하다고한다.
cf) 데이터에 가장 알맞는 layer의 차원은 정확히 평가할 수 없다고 한다. --> 차원은 단지 정보량을 대략적으로 추정하기 위한 지표
2.2. Higher Dimensional representations 효과적으로 처리!
- Higher Dimensional Representation을 잘 포착하려면,
- CovL에서 각 tile당 activation function을 적용하는 횟수를 증가시키면 가능하다.
- 학습 속도가 더 빨라질 수 있다.
2.3 Spatial Aggregation(Convolution) 전 차원 축소
- Convolution하기 전에 차원 축소를 하게된 큰 정보 손실없이 저차원 채널로 매핑할 수 있다.
2.4. network의 width와 depth의 균형맞추기
- network의 성능을 최적화하려면 각 단계에서 filter의 개수(width)와 network의 depth를 균형있게 조절해야 한다.
- network의 width와 depth 동시에 증가시키면 성능 향상에 기여할 수 있다.
3. Factorizing Convolutions with Large Filter Size
- GoogLenet의 성능 향상의 상당 부분은 Dimension reduction를 활용했기 때문이다.
- Convolution을 효율적으로 factorization을 했다고 볼 수 있다.
3.1. Factorization into Smaller Convolutions
- VGGNet에서 쓰인 아이디어를 인용하게 되었다.
- 5x5,7x7의 filter를 3x3 filter n개로 factorization가능하다.
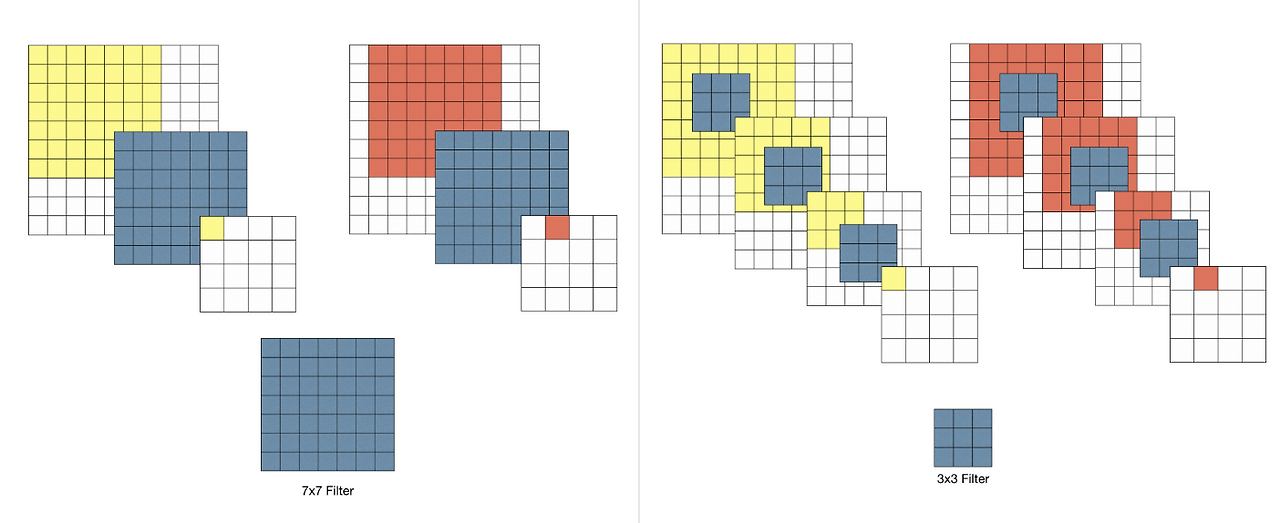
- 왜 사이즈가 큰 필터 대신 3x3 필터 여러 개를 쌓는 방식을 선택한 이유는 무엇일까?
- ex) 7x7 필터는 3x3필터를 3개를 연속으로 사용한것과 동일한 receptive filed를 갖는다.
- 3개를 연속으로 사용하기 때문에 ReLU를 3번 적용하게 되어 non-linearity가 증가하게 된다.
- 뿐만 아니라, 학습되는 parameter의 개수도 감소하게 된다.
ex) 7 x 7 filter 1개 : 7 x 7 x C^2 = 49C^2
3 x 3 filter 3개 : 3x3x3xC^2 = 27C^2
- 이는 곧, 동일한 효과를 보이면서 Overfitting을 억제시켜주는 역할을 하게 된다.
- 그래서 기존의 Inception v1에서 5x5 filter를 3x3 filter 2개로 분해한다.
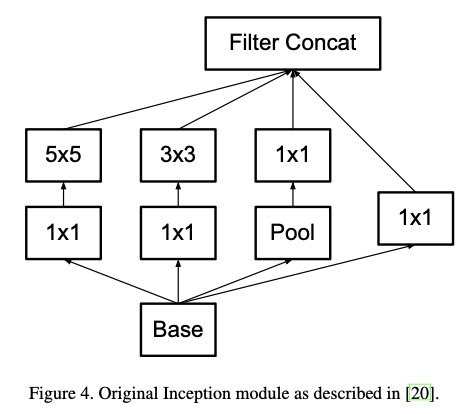 |
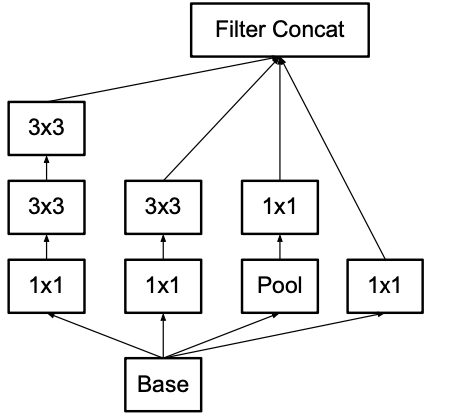 |
- 추가적으로 해당 논문에서 3x3 filter들로 factorization할때, activation function을 다 넣냐,안넣냐에 따라 실험을 진행하였다.
- 그 결과 모두 ReLU같은 non-linear activation function을 취해주는게 더 성능이 좋다고 한다.

3.2. Spatial Factorization into Asymmetric Convolutions
- 우리는 3x3보다 큰 필터는 3x3필터 n개로 분해하는게 더 효과적이라는 것을 알고 있다.
- 그러면 3x3보다 더 작은 filter로 분해한다면, 더 성능이 좋아질까?
- 실제로 실험을 진행해보았을 떄, 2x2 convolution을 이용하는 것보다,
- asymmetric convolutions을 사용하는것이 훨씬 더 효과적이라는 것을 밝혔다.
- 본 논문에선, nx1 convolution과 1xn convolution을 조합하는 방식이 훨씬 효율적이라고 한다.
- 즉, 3x3 convolution을 3 x 1과 1 x 3 으로 분해한다면, 동일한 receptive field를 가지면서,
- 계산비용을 크게 절감할 수 있다고 한다.
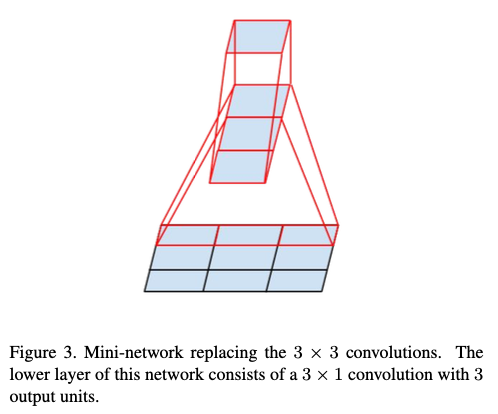
- asymmetric convolution이 모든 상황에서 효과적이진 않다.
- network의 early layers에선 이 기법이 잘 작동되지 않는다고 한다.
- 하지만, m x m feature maps에서 m이 12~20사이인 경우 매우 좋은 결과를 보인다고 한다.
cf) 위에서의 Inception에서 다음과 같이 적용가능하다.
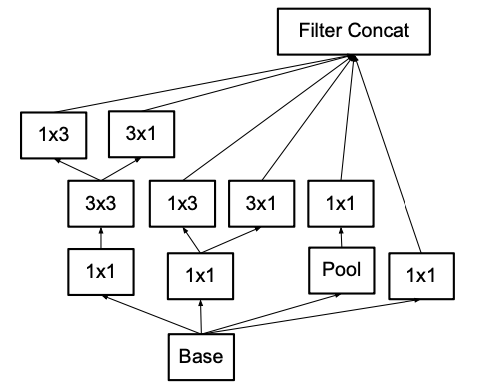
4. Utility of Auxiliary Classifiers
- 초기 논문에선, graident vanish가 발생하지 않도록 중간 중간 Gradient를 보내주었다고 한다,
- 하지만, 유의미하진 않다고 한다. 다만, Auxiliary Classifier의 위치에 dropout이나 batch normalization을 적용하면 좋다고 한다.
5. Efficient Grid Size Reduction
-일반적으로 CNN은 feature map의 사이즈를 줄이기 위해, pooling을 사용한다.
- 다만 이렇게 되면 정보량이 줄어들기 때문에, 그만큼 필터 수를 증가시켜 정보량을 거의 일치하게 만들어준다.
ex) (dxd,k개) -- Pooling --> ((d/2) x (d/2), 4k개)
- 본 논문에선 다음과 같이 진행하였다.
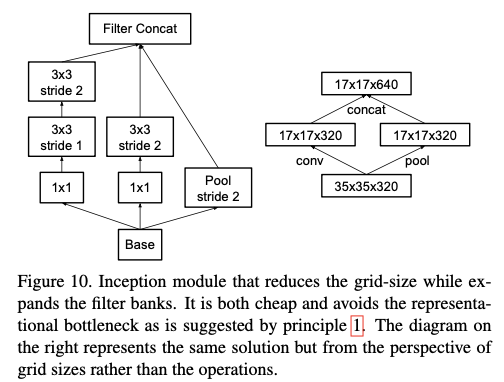
6. Inception-v2
- 다음과 같이 구현되었다.
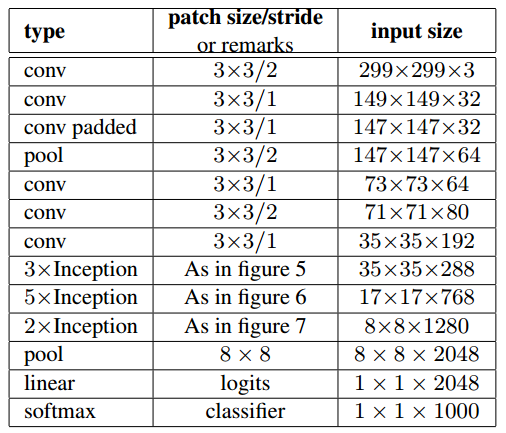
- figure 5
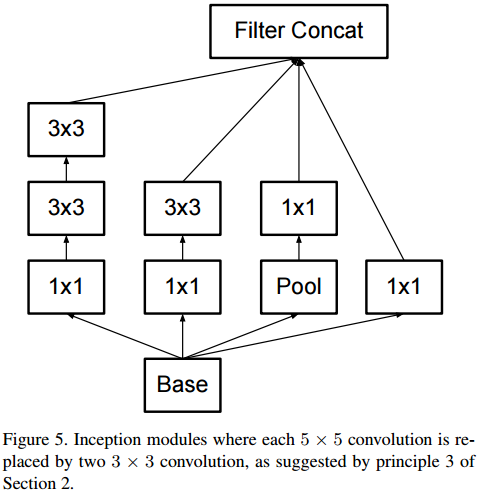
- figure 6

- figure 7

7. Model Regularization via Label Smoothing
- Label Smoothing은 Normalization기법중 하나로, 간단하면서 모델의 generalization을 높여주는 기술이라고 한다.
- 간단히, 레이블을 다음과 같이 [1,0,0,0] -- Label Smoothing --> [0.925,0.025,0.025,0.025]로
- 모델이 강한 확신하는 걸 감소시켜준다고 생각하면 좋다.
- (자세한 내용은 "When Does Label Smoothing Help?"논문을 참고하여 따로 리뷰하도록 하겠습니다.)
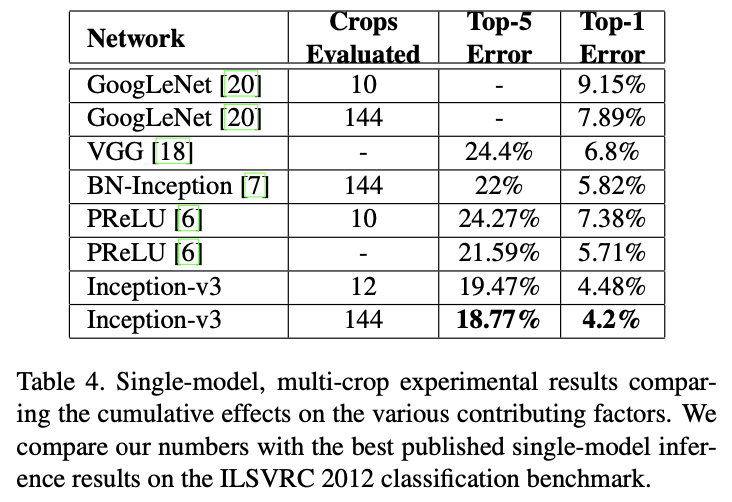
8. Inception v3

'Paper Review(논문 리뷰) > Computer Vision' 카테고리의 다른 글
| [논문 리뷰] [CV] Delving Deep into Rectifiers:Surpassing Human-Level Performance on ImageNet Classification (0) | 2025.03.21 |
|---|---|
| [논문 리뷰] [CV] Deep Residual Learning for Image Recognition (0) | 2025.03.21 |
| [논문 리뷰] [CV] Going deeper with convolutions (0) | 2025.03.18 |
| [논문 리뷰] [CV] VERY DEEP CONVOLUTIONAL NETWORKSFOR LARGE-SCALE IMAGE RECOGNITION (0) | 2025.03.17 |
| [논문 리뷰] [CV] Network In Network (0) | 2025.03.17 |