
0. Reference
https://arxiv.org/abs/1512.03385
Deep Residual Learning for Image Recognition
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with
arxiv.org
1. Introduction
- 해당 논문은 "더 성능이 좋은 Network를 만들기 위해서, 단순히 layer를 추가하면 될까?"라는 질문에서 시작되었다.
- Network의 깊이가 증가함에 따라 정확도가 일정수준에서 saturated되는 것을 확인할 수 있었다고 한다.
- 근데, 놀랍게도 Overfitting이 문제가 아니라고 하며, training error가 증가하는 현상이 관찰되었다고 한다.
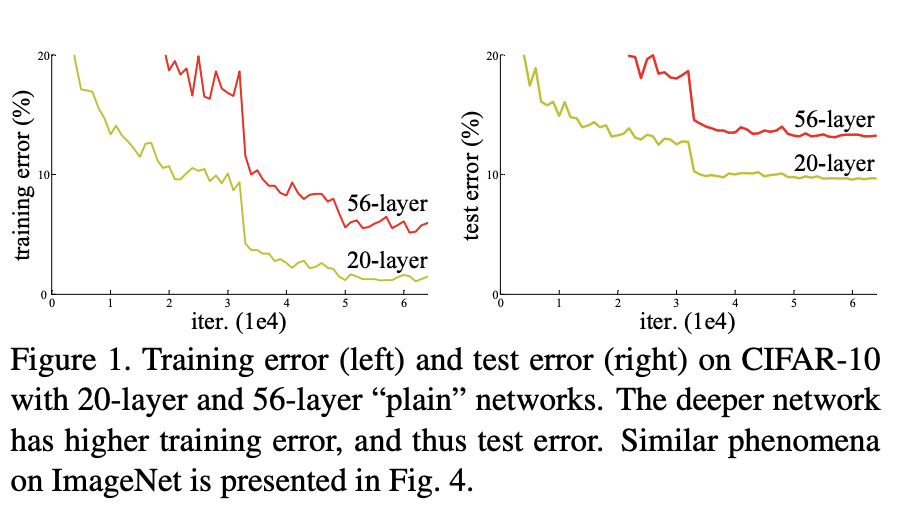
- Depth-model과 Shallow-model을 비교하였을 때,
- 그냥 단순히 Depth-model을 Shallow-model에 identity mapping만 더해준 형태라고 생각하면,
- 이 둘의 error의 차이는 이론적으로 크지 않아야 된다.
- 하지만, Depth model의 성능이 더 떨어지게 되는데(Degradation problem),
- 그 이유는 Optimization이 depth model에서 Optimal solution을 찾기 힘든 아이이기 때문이다.
- cf) Gradient vanish나 gradient explode가 발생할 가능성이 높다.
2. Deep Residual Learning
2.1. Residual Learning
- 기존의 Deep learning model이 학습을 하는 방식은 다음과 같다.
- x -------> H(x)
- resnet이 학습하는 방식은 다음과 같다.
- H(x) = x + f(x) #여기서 f(x)만 learning되고, x는 not learning된다.
- 핵심 아이디어는 다음과 같다. 우리가 앞서서 단지 H(X)자체를 Identity function으로 근사하는게 목적이라고 생각하자.
- 그러면 기존의 Deep learning방식은 x를 I(x)로 완전히 다르게 mapping시켜야 하지만,
- Resnet방식을 잘 보면, 그냥 f(x)를 0으로 이루어진 tensor로만 만들어주면 H(x) = x가 되면서 Identity mapping이 가능하게 된다.
- 즉, Residual Learning 방식이 보다 편하게 학습된다는 것을 알 수 있다.
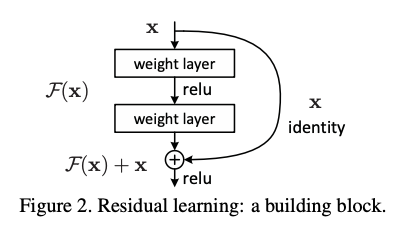
cf) 여기서 x를 더해주는 과정을 Shortcut Connection이라고 한다.
2.2. Identity Mapping by Shortcuts
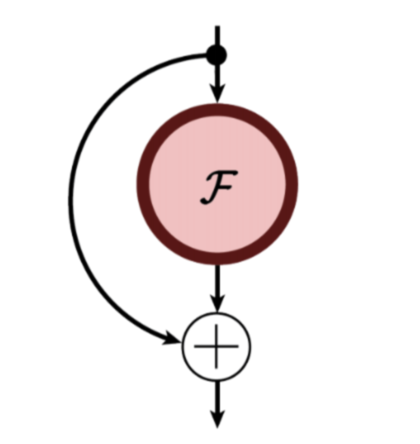
- Residual learning이 일어나는 block을 우리는 Residual block이라고 정의하자.
- Residual block를 수식으로 나타내면 다음과 같다.
y = f(x,wi) + x # + x : Shortcut connection
f(x,wi) = max(wi^Tx,0)
- 여기서, x와 f(x,wi)와의 dimension이 다를 경우, identity mapping하여 dimension을 같게 만들어준다.
- 이과정은 broadcasting과 유사한 작업이라고 생각하면 좋다.
cf) 아래 그림처럼 Affine층을 한번만 거치는 Residual Learning은 효과가 없다고 한다.
2.3. Architecture
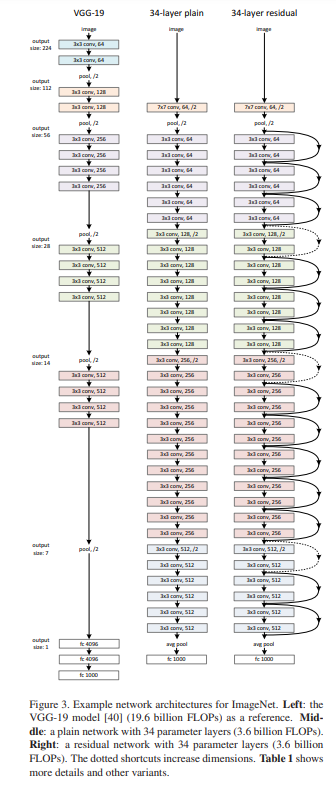
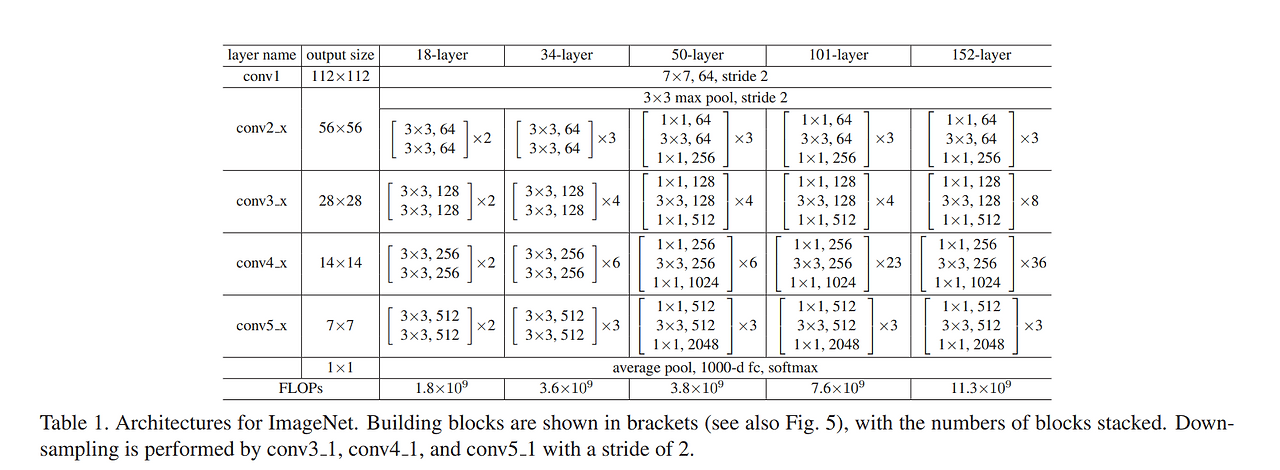
- 결과적으로 152 layer까지 쌓아올렸다고 한다.
'Paper Review(논문 리뷰) > Computer Vision' 카테고리의 다른 글
0. Reference
https://arxiv.org/abs/1512.03385
Deep Residual Learning for Image Recognition
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with
arxiv.org
1. Introduction
- 해당 논문은 "더 성능이 좋은 Network를 만들기 위해서, 단순히 layer를 추가하면 될까?"라는 질문에서 시작되었다.
- Network의 깊이가 증가함에 따라 정확도가 일정수준에서 saturated되는 것을 확인할 수 있었다고 한다.
- 근데, 놀랍게도 Overfitting이 문제가 아니라고 하며, training error가 증가하는 현상이 관찰되었다고 한다.
- Depth-model과 Shallow-model을 비교하였을 때,
- 그냥 단순히 Depth-model을 Shallow-model에 identity mapping만 더해준 형태라고 생각하면,
- 이 둘의 error의 차이는 이론적으로 크지 않아야 된다.
- 하지만, Depth model의 성능이 더 떨어지게 되는데(Degradation problem),
- 그 이유는 Optimization이 depth model에서 Optimal solution을 찾기 힘든 아이이기 때문이다.
- cf) Gradient vanish나 gradient explode가 발생할 가능성이 높다.
2. Deep Residual Learning
2.1. Residual Learning
- 기존의 Deep learning model이 학습을 하는 방식은 다음과 같다.
- x -------> H(x)
- resnet이 학습하는 방식은 다음과 같다.
- H(x) = x + f(x) #여기서 f(x)만 learning되고, x는 not learning된다.
- 핵심 아이디어는 다음과 같다. 우리가 앞서서 단지 H(X)자체를 Identity function으로 근사하는게 목적이라고 생각하자.
- 그러면 기존의 Deep learning방식은 x를 I(x)로 완전히 다르게 mapping시켜야 하지만,
- Resnet방식을 잘 보면, 그냥 f(x)를 0으로 이루어진 tensor로만 만들어주면 H(x) = x가 되면서 Identity mapping이 가능하게 된다.
- 즉, Residual Learning 방식이 보다 편하게 학습된다는 것을 알 수 있다.
cf) 여기서 x를 더해주는 과정을 Shortcut Connection이라고 한다.
2.2. Identity Mapping by Shortcuts
- Residual learning이 일어나는 block을 우리는 Residual block이라고 정의하자.
- Residual block를 수식으로 나타내면 다음과 같다.
y = f(x,wi) + x # + x : Shortcut connection
f(x,wi) = max(wi^Tx,0)
- 여기서, x와 f(x,wi)와의 dimension이 다를 경우, identity mapping하여 dimension을 같게 만들어준다.
- 이과정은 broadcasting과 유사한 작업이라고 생각하면 좋다.
cf) 아래 그림처럼 Affine층을 한번만 거치는 Residual Learning은 효과가 없다고 한다.
2.3. Architecture
- 결과적으로 152 layer까지 쌓아올렸다고 한다.