
0. Reference
https://arxiv.org/abs/1906.02629
When Does Label Smoothing Help?
The generalization and learning speed of a multi-class neural network can often be significantly improved by using soft targets that are a weighted average of the hard targets and the uniform distribution over labels. Smoothing the labels in this way preve
arxiv.org
1. Introduction
- Classification,Speech recognition, Machine trainslation등등 Label smoothing은 많이 쓰이는 기법중 하나이다.
- 근데, 해당 논문이 나오기 전까진, 왜 이게 좋은지 모른 상태로 쓰는 경우가 많았다고 한다.
- 본 논문에선, Label Smoothing이 무엇인지 설명해고, 이를 적용한 Network의 동작방식을 설명하고,
- 이를 적용한 Network의 특징을 기술하고 있다.
- 즉, 종합적으로 Label Smoothing에 대한 전반적인 가이드라인을 제공해주는 논문이라고 생각하면 좋다.
1.1. Preliminaries
- 본격적으로 진행하기 전에, Label Smoothing이 무엇인지 같이 알아보자.
- 우선, Cross Entropy를 Loss Function으로 사용하는 Network가 있다고하자.
- 그럼 우리는 Softmax Function을 거쳐 Probability Vector로 변환하고

- Probability Vector를 Cross entropy에서, 실제 target과 비교하여 Gradient descent를 진행하게 된다.

- 여기서, target은 보통 [0,0,1,0,0,0]처름 one hot encoding되어 있는 상태이다.
- 이는 마치 확률적 관점으로 봤을 때 정답일 확률을 100%, 나머지를 0%로 잡는다고 생각할 수 있디.
- 이를 Hard targets이라고 정의한다.
- 여기서 Hard targets을 좀 Soft하게 변환해주게 되는 기법을 Label Smoothing이라고한다.
- 식은 다음과 같다.

- 여기서 alpha는 hyper-parameter인데, 해석은 다음과 같이하면 된다.
- 정답인 1에 alpha만큼 빼주고, 모든 값에다가 alpha/(레이블개수) 만큼 더해주면 된다.
ex)
[1,0,0,0] -- alpha = 0.4--> [1-0.4+0.1,0.1,0.1,0.1] = [0.7,0.1,0.1,0.1]
2. Penultimate Layer representations
- label smoothing을 적용한 Network의 train은 answer의 logit과 error의 logit간의 차이를
- alpha에 따라 일정한 값으로 유지하도록 유도한다.
cf) logit이란?
- logistic regression 및 network에서 사용되는 개념으로,
- 특정 class에 대한 예측값을 softmax function에 적용하기 이전의 출력값을 의미한다.
- 즉, Output layer에서 (softmax or sigmoid)을 적용하기 전의 Linear transformation의 결과를 의미한다.
- x^Tw 형태라고 생각하면 좋다.
- Label Smoothing이 왜 효과적인지 수식으로 알아보자.
- 우선 Loss Function으로 Cross Entropy를 쓴다고 가정하자.
- 우선 Hard targets을 사용하고 있을 때 먼저 보자.
- 일반적으로 분류 문제에서 사용하는 Loss Function은 다음과 같다.

- 여기서, Hard target이기 때문에, 정답 class만 제외하고 나머지는 y가 0 이 된다.

- 결과론적으로, 해당 Loss Function을 통해서 Back-propagation을 진행할 때,
- 거의, 정답 class에 대해서만 집중적으로 학습되게 된다.
- Label Smoothing을 적용한 경우,
- 즉, Soft target을 사용하는 경우 다음과 같다.
- 우선 label은 다음과 같이 조정된다.

- 이를 Cross Entropy에 대입하게 되면 다음과 같다.
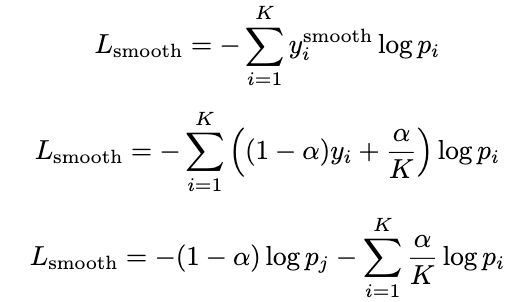
- 즉, 기존의 Cross entropy와 다르게, 정답 class에 대해서만 집중적으로 학습하는 것이 아니고,
- 오답 class에 대해서도 적절히 학습할 기회를 주는 방식이 된다고 생각하면 좋다.
- 즉 이로인해 모델이 Over-confidence를 하게되는 경향을 줄여주게 된다. --> Over-fitting 억제해주는 역할도 한다.
- 추가적으로, 논문에선 Label smoothing이 Penultimate layer의 활성화 값이
- 정답 클래스의 템플릿에 가깝도록 유도하며, 동시에 오답 클래스들의 템플릿과는 동일한 거리를 유지하도록 만들어 준다고 한다.
- 본 논문에서 Label Smoothing의 특성을 관찰하기 위해 새로운 visualization을 제안하였다.
"""
i) 세 개의 class를 선택한다.
ii) 이 세 개의 class의 weight를 포함하는 평면에 대한 orthonormal basis를 찾는다.
iii) 선택한 세 개의 class에 대한 Penultimate layer의 활성화 값을 해당 평면의 projection한다
"""

- Label Smoothing을 적용하니, 클러스터가 훨씬 더 밀집되어 있는 모습을 볼 수 있다.