
0. Reference
https://arxiv.org/abs/1602.07261
Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
Very deep convolutional networks have been central to the largest advances in image recognition performance in recent years. One example is the Inception architecture that has been shown to achieve very good performance at relatively low computational cost
arxiv.org
1. Introduction
- 기존의 Inception구조에 residual connection을 결합하여 성능향상이 되는지, 연구하고자 하였다.
- 해당 논문에선 Inception-v4, Inception-ResNet-v2, 그리고 여러 모델(총 4개)을 앙상블하여 실험을 진행하였다고 한다.
2. Related Work
- Residual Connection
https://ceulkun04.tistory.com/225
- Inception
https://ceulkun04.tistory.com/222
3. Architectural Choices
3.1. Pure Inception blocks
- 기존의 inception v1,v2,v3는 필요 이상으로 복잡한 네트워크 구조였다고 한다.
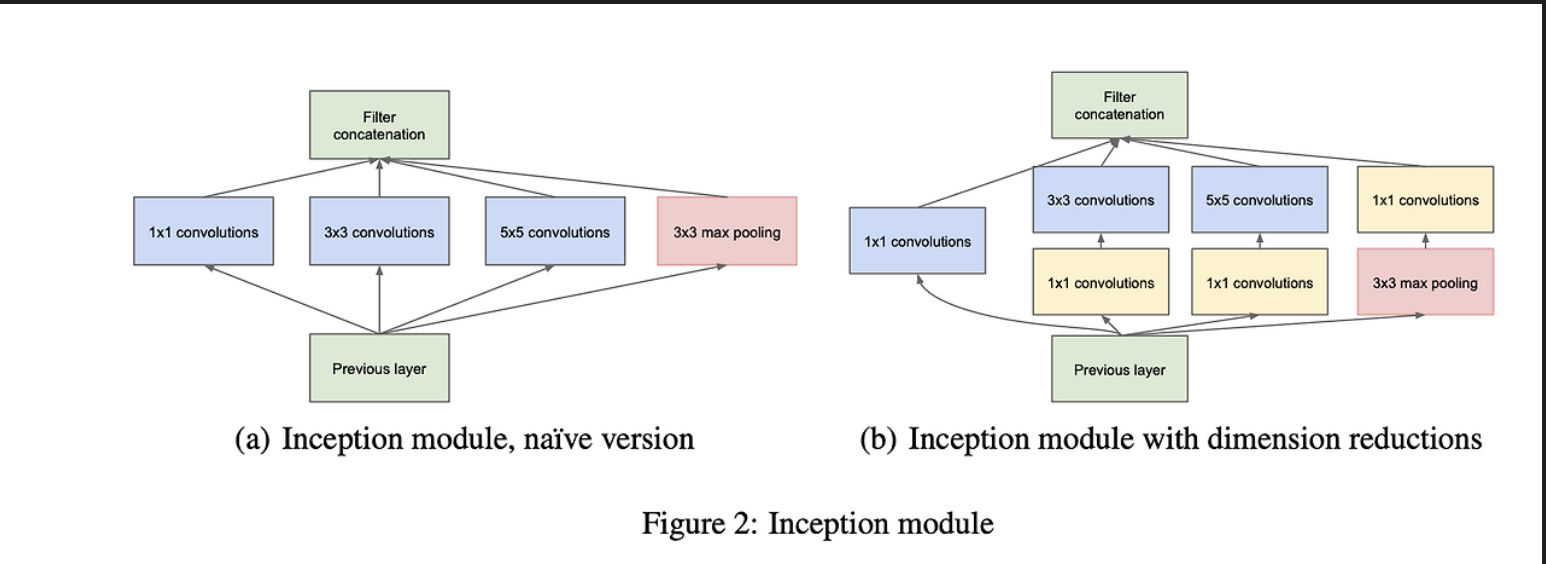
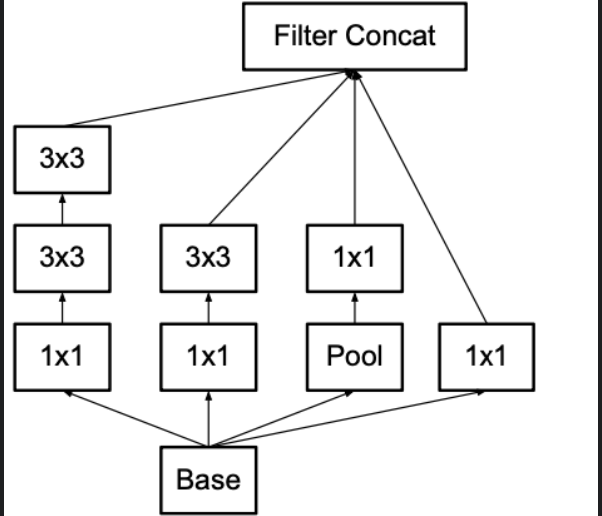

- Inception v4에선 불필요한 Complexity를 제거하고,
- 각 grid size마다 inception을 일관된 방식으로 구성하기로 결정하였다고 한다.
- Inception v4의 전체 구조는 다음과 같다.

- 좀 더 세부적으로 봐보자
i) Input --> Stem

ii) Stem --> Inception A

iii) Inception A --> Inception B

iv) Inception B --> Inception C

v) Reduction module

3.2. Residual Inception blocks
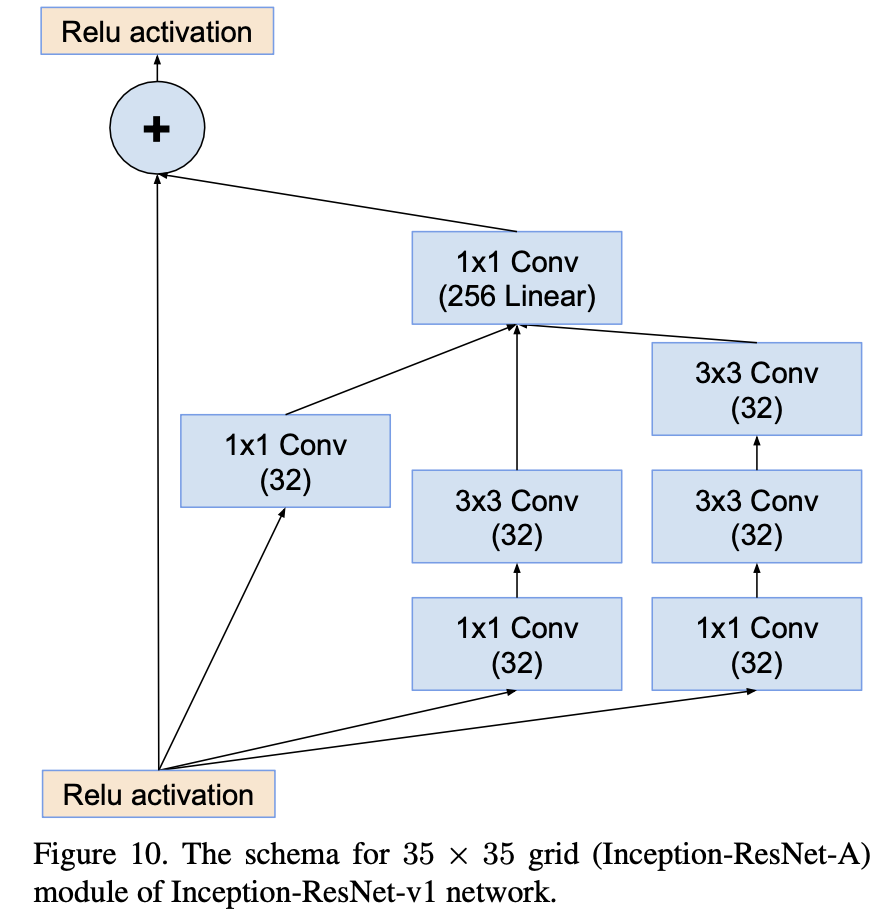
- Residual Inception은 기존 Inception보다 더 가벼운 Inception block를 사용한다.
- 각 Inception block뒤에는 filter-expansion layer가 따라붙는데,
- 이는 activation function없이 1x1 convolution을 사용해, 입력과 출력의 depth를 맞추기 위해 filter bank의 차원을 확장한다.
- 이 이유는, Inception block내에서 발생하는 dimensionality reduction을 보완하기 위한 과정이라고 보면 된다.
- 본 논문에선 Inception-Resnet-v1과 Inception-Resnet-v2가 존재한다.
- Inception-Resnet-v1은 Inception-v3와 비슷한 계산량을 가지고 있으며,
- Inception-Resnet-v2는 Inception-v4와 비슷한 계산량을 가진다.
- 다음과 같은 구조를 가진다.

- Inception-ResNet-v1의 구조를 먼저 자세히 확인해 보자.
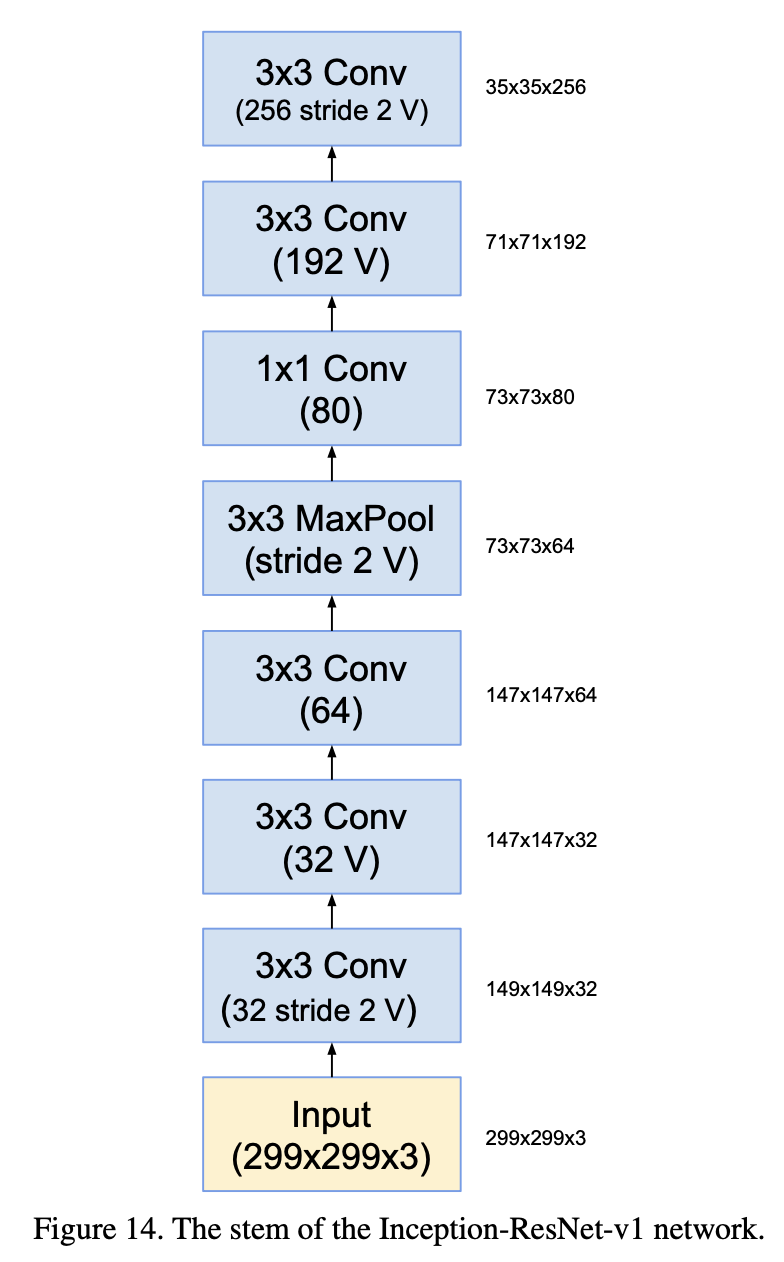 |
 |
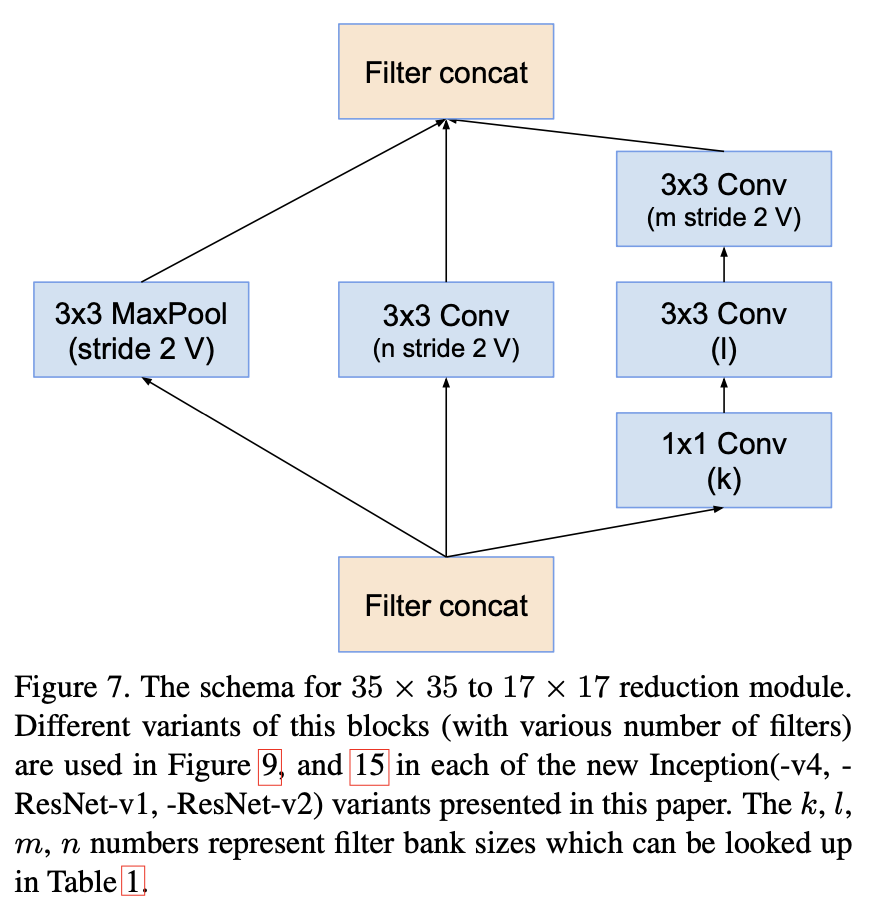 |
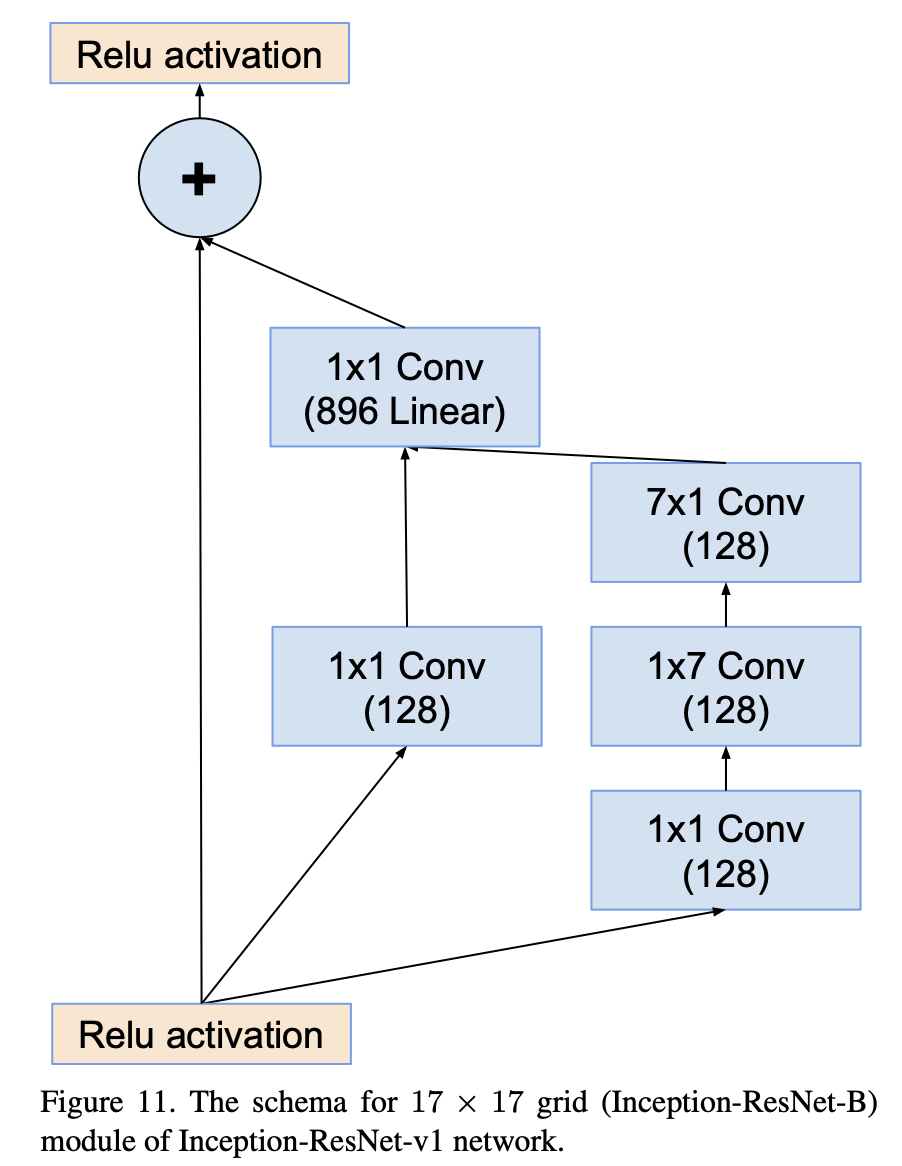 |
 |
 |
- Inception-Resnet-v2의 구조는 다음과 같다.
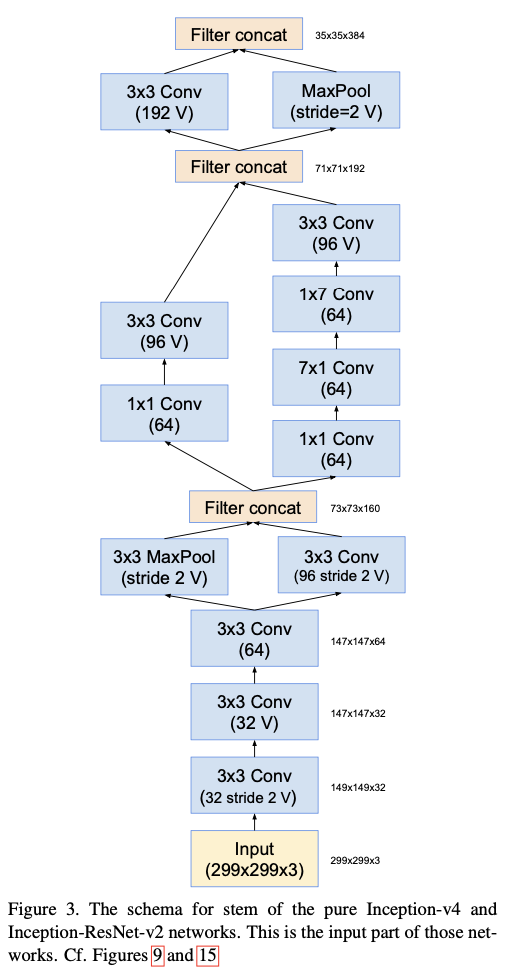 |
 |
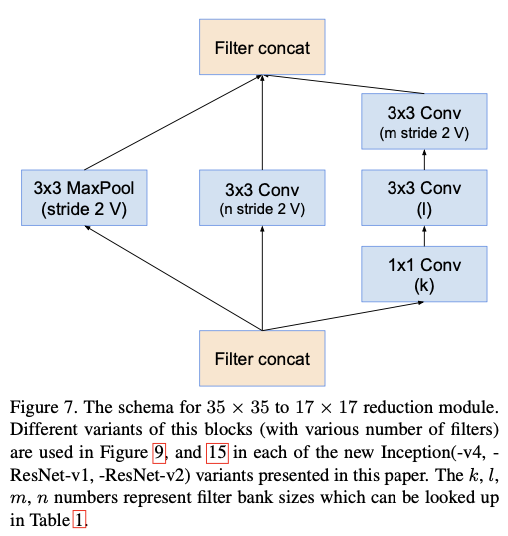 |
 |
 |
 |
- 본 논문에선, BN에 대해 전체 레이어에 적용하지 않은 이유를 기술하였는데,
- 그 이유가 제가 느끼기엔 부족한 논리라고 생각하여, 리뷰에 포함하진 않겠습니다.
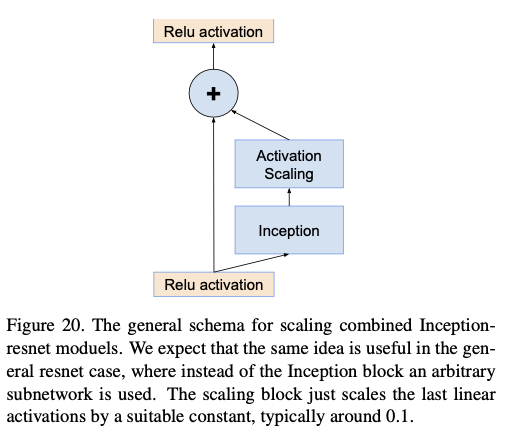
3.3. Scaling of the Residuals
- 필터 수가 1000개를 초과하면 , Residual block를 사용하는 경우,
- Average Pooling직전에 모든값이 0만 출력되는, 'dying' 현상이 관찰되었다고 한다.
- 이문제를 BN을 적용하거나, lr를 낮추거나하는 것으로 해결되지 않았다고 한다.
- 이를 해결하기 위해, residual을 이전 층의 출력에 더하기 전에 스케일을 줄여주는 것이 학습을 안정시킨다고 한다.
- 여기서 스케일을 줄여주는 것이 어떤의미인지 확인하기 위해 코드를 직접 확인을 해보니, 출력값을 줄여주는 의미로 사용되었다.

- 본 논문에선, 0.1~0.3 사이의 스케일 계수를 사용하여 Residual을 줄인 뒤, 이전 계층의 출력을 더했다고 한다.
4. Training Methodlogy
- Optimizer로 RMSProp을 사용하였고(decay = 0.9, epsilon = 1.0)
- lr은 0.045로 설정하였으며, 2 epoch마다 0.94를 곱하면서 lr를 줄여나갔다고 한다.
- 그리고 모델의 파라미터를 업데이트하는 과정에서, Exponential Moving Average를 사용하여.
- 마지막 step만 고려하는 것이 아니라, 마지막 부근의 여러 step을 고려하여 파라미터를 업데이트하여,
- generalization을 키웠다고 한다.
5. Conclusion
- 성능은 다음과 같다고 한다.
- Inception-ResNet-v1 <<<< Inception-v4 <<<< Inception-resnet-v2
'Paper Review(논문 리뷰) > Computer Vision' 카테고리의 다른 글
| [논문 리뷰] [CV] Wide Residual Networks (1) | 2025.03.26 |
|---|---|
| [논문 리뷰] [CV] Highway Networks (0) | 2025.03.23 |
| [논문 리뷰] [CV] Delving Deep into Rectifiers:Surpassing Human-Level Performance on ImageNet Classification (0) | 2025.03.21 |
| [논문 리뷰] [CV] Deep Residual Learning for Image Recognition (0) | 2025.03.21 |
| [논문 리뷰] [CV] Rethinking the Inception Architecture for Computer Vision (0) | 2025.03.19 |