
0. Reference
https://arxiv.org/abs/1608.06993
https://www.youtube.com/watch?v=fe2Vn0mwALI&list=PLlMkM4tgfjnJhhd4wn5aj8fVTYJwIpWkS&index=29
Densely Connected Convolutional Networks
Recent work has shown that convolutional networks can be substantially deeper, more accurate, and efficient to train if they contain shorter connections between layers close to the input and those close to the output. In this paper, we embrace this observa
arxiv.org
1. Introduction
- 우선 우리가 알고있는 CNN의 기본 구조는 다음과 같다.

- 여기서, Skip Connection을 도입한 꼴은 다음과 같다.

- 여기서 DenseNet은 그 다음 layer에만 연결하는게 아니라 모든 layer에 연결하겠다라는 아이디어를 도입한다.
- 여기서, 위 방식과 다른점은 합쳐질때, Sum이 아니라 concatenation이 작동된다는 것이다.

- 이렇게 연결하면 상식적으로, 너무 Model의 complexity가 올라간다고 생각이 들것이다.
- 그래서, 각 layer의 Channel을 줄여준다.(여기서 k는 growth rate라고 정의된다.-->hyper-parameter.)

- 과연, 이를 어떻게 학습할 수 있을까? forward 입장에서 먼저 봐보면 다음과 같다.


- BN --> ReLU --> ConV로 진행이 되는데, 이는 마치 Wild Residual Network논문에서 주장한것과 똑같다.
- 전체 구조는 아래그림과 같다.
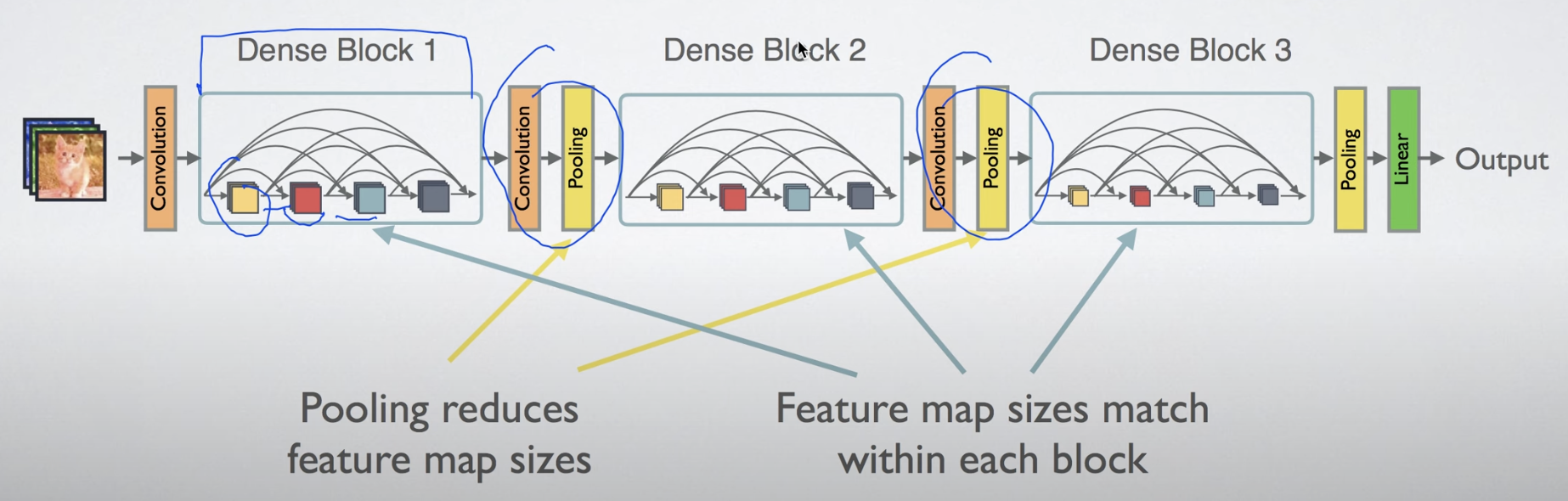
2. Advantage
- DenseNet은 Backpropagation에 유리한 구조를 보이고 있다.

- gradient vanish가 발생하기 좀 어렵다. 그 이유는 Error signal을 모든 layer에 전달하기 때문이다.
- 기존의 CNN은 Feature Extracter - Classifier로 구성되어 있는데,
- 생각해보면, Feature Extracter의 마지막 layer의 feature map만 가지고 Classify를 하게 된다.
- 즉, 앞에 정보들은 Classifer에 전달되지 못하고, 사라진다라고 생각이 가능하다.

- DenseNet같은경우 Concatenate하기 때문에, 모든 layer의 feature map을 고려할 수 있게 된다.

3. Conclusion

'Paper Review(논문 리뷰) > Computer Vision' 카테고리의 다른 글
0. Reference
https://arxiv.org/abs/1608.06993
https://www.youtube.com/watch?v=fe2Vn0mwALI&list=PLlMkM4tgfjnJhhd4wn5aj8fVTYJwIpWkS&index=29
Densely Connected Convolutional Networks
Recent work has shown that convolutional networks can be substantially deeper, more accurate, and efficient to train if they contain shorter connections between layers close to the input and those close to the output. In this paper, we embrace this observa
arxiv.org
1. Introduction
- 우선 우리가 알고있는 CNN의 기본 구조는 다음과 같다.
- 여기서, Skip Connection을 도입한 꼴은 다음과 같다.
- 여기서 DenseNet은 그 다음 layer에만 연결하는게 아니라 모든 layer에 연결하겠다라는 아이디어를 도입한다.
- 여기서, 위 방식과 다른점은 합쳐질때, Sum이 아니라 concatenation이 작동된다는 것이다.
- 이렇게 연결하면 상식적으로, 너무 Model의 complexity가 올라간다고 생각이 들것이다.
- 그래서, 각 layer의 Channel을 줄여준다.(여기서 k는 growth rate라고 정의된다.-->hyper-parameter.)
- 과연, 이를 어떻게 학습할 수 있을까? forward 입장에서 먼저 봐보면 다음과 같다.
- BN --> ReLU --> ConV로 진행이 되는데, 이는 마치 Wild Residual Network논문에서 주장한것과 똑같다.
- 전체 구조는 아래그림과 같다.
2. Advantage
- DenseNet은 Backpropagation에 유리한 구조를 보이고 있다.
- gradient vanish가 발생하기 좀 어렵다. 그 이유는 Error signal을 모든 layer에 전달하기 때문이다.
- 기존의 CNN은 Feature Extracter - Classifier로 구성되어 있는데,
- 생각해보면, Feature Extracter의 마지막 layer의 feature map만 가지고 Classify를 하게 된다.
- 즉, 앞에 정보들은 Classifer에 전달되지 못하고, 사라진다라고 생각이 가능하다.
- DenseNet같은경우 Concatenate하기 때문에, 모든 layer의 feature map을 고려할 수 있게 된다.
3. Conclusion