0. Reference
https://arxiv.org/abs/1610.02357
Xception: Deep Learning with Depthwise Separable Convolutions
We present an interpretation of Inception modules in convolutional neural networks as being an intermediate step in-between regular convolution and the depthwise separable convolution operation (a depthwise convolution followed by a pointwise convolution).
arxiv.org
1. Inception Hypothesis
- 우선 Xception에 대해서 알아가기 전에, Inception에 대해서 딥하게 알아가보자.
- 우선, Single ConVLayer의 특징을 먼저보자.
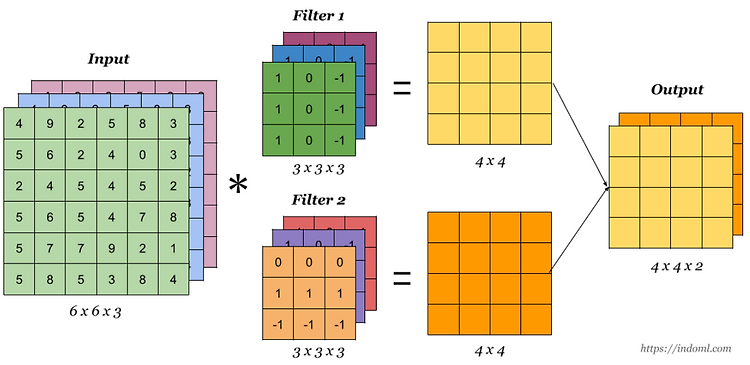
- Single ConVLayer는 Channel과 Channel간의 관계, 또는 patch와 patch간의 관계를 Dependent하게 feature를 생성한다.
- 그 이유는 Convolution이 그 역할을 하기 때문이다.

- 반면에 Inception은 Channel <--> Channel 과 Patch <--> Patch 간의 feature를 Independent하게 뽑아낸다.
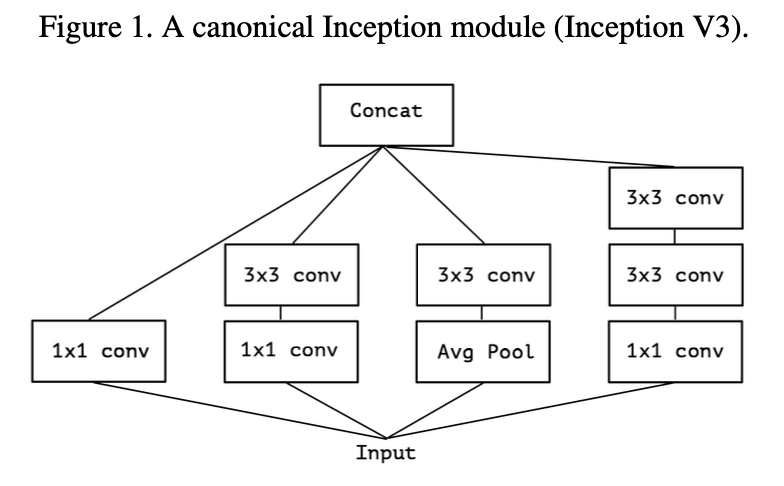
- Channel간의 feature는 1x1 Convolution이 뽑아내고,
- Patch간의 feature는 3x3 COnvolution이 뽑아내게 된다.
- 이렇게 Independent하게 진행되기에, 성능이 더 좋았다고 한다.
- 여기서 Avg Pooling을 제외하고, 좀 더 Inception을 간소화해보자.
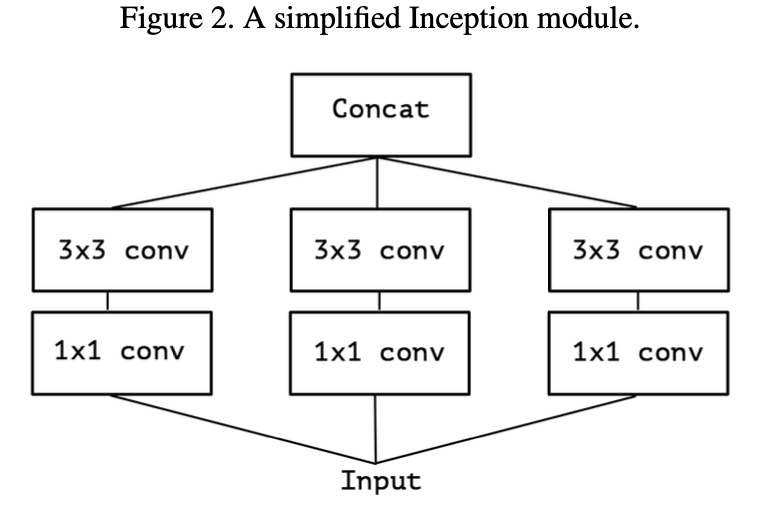
- 이는 1x1 ConV으로 input보다 많은 Channel을 만들어낸다고 생각할 수 있다.
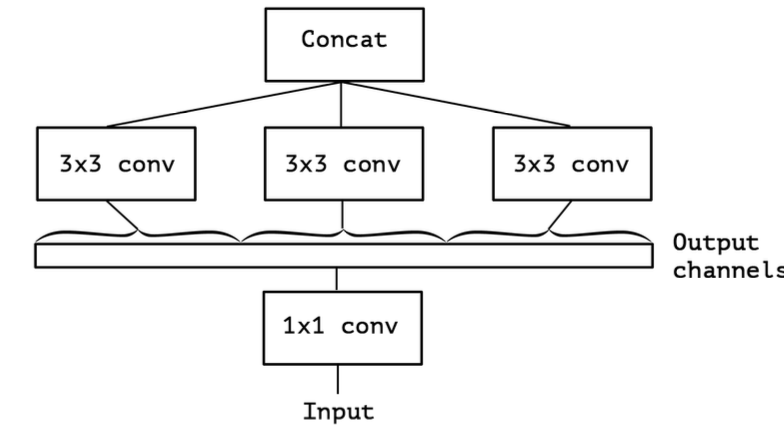
- 즉, 1 x 1 conv이 만들어낸 Channel을 Non-overlapping하여 ConV을 진행하는것과 유사하다.
- 이 과정을 좀 더 일반화 하면 다음과 같다.
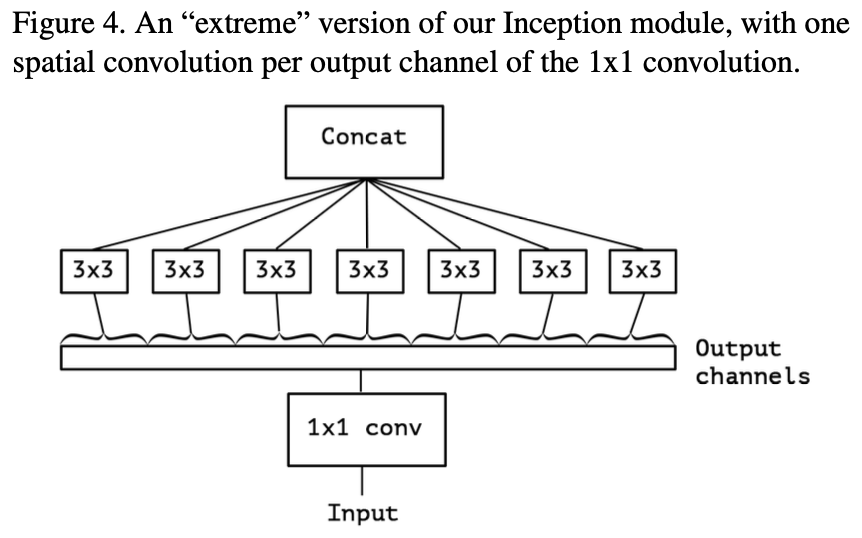
- 이러한 형태를 우리는 Xception(Extreme Inception)이라고 정의한다.
- 기존의 Inception의 Independent한 특징이 더더욱 강하게 Independent하게 만들어 줬다고 생각하면 좋다.
- 이러한 형태는 마치, Depthwise Separable Convolution과 유사하다고 한다.
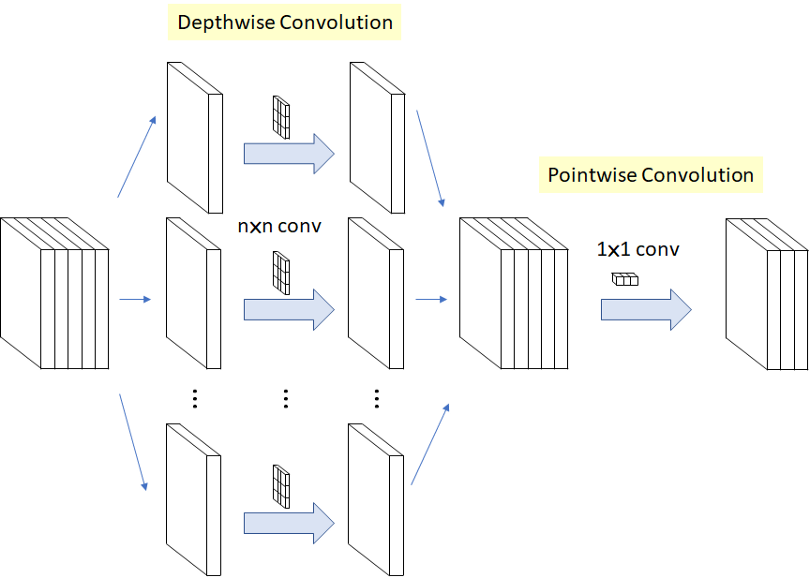
- Depthwise Separable Convolution은 기존의 input channel개수만큼 3x3으로 진행되어 concat하고 그 후 1x1을 통해 Squeeze한다.
- 여기서 3x3 ConV할때, Activation function을 적용하지 않았는데,
- 그 이유는 channel 한개만 사용하는 얇은 feature map에 activation function을 사용하게 되면, 정보손실이 발생한다고 한다.